

【python】爬取豆瓣电影排行榜Top250存储到Excel文件中【附源码】
英杰社区 https://bbs.csdn.net/topics/617804998
https://bbs.csdn.net/topics/617804998
一、背景
近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程

(图片来源网络,侵删)
序,用于抓取豆瓣电影Top250的相关信息,并将其保存为Excel文件。
程序包含以下几个部分:
导入模块:程序导入了 BeautifulSoup、re、urllib.request、urllib.error、xlwt等模块。
定义函数:
- geturl(url):接收一个URL参数,返回该URL页面内容。
- getdata(baseurl):接收一个基础URL参数,遍历每一页的URL,获取电影信息数据,以列表形式返回。
- savedata(datalist,savepath):接收电影信息数据和保存路径参数,将数据保存到Excel文件中。
二、导入必要的模块:
代码首先导入了需要使用的模块:requests、lxml和csv。
import requests from lxml import etree import csv
如果出现模块报错
(图片来源网络,侵删)
进入控制台输入:建议使用国内镜像源
pip install 模块名称 -i https://mirrors.aliyun.com/pypi/simple
我大致罗列了以下几种国内镜像源:
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple 阿里云 https://mirrors.aliyun.com/pypi/simple/ 豆瓣 https://pypi.douban.com/simple/ 百度云 https://mirror.baidu.com/pypi/simple/ 中科大 https://pypi.mirrors.ustc.edu.cn/simple/ 华为云 https://mirrors.huaweicloud.com/repository/pypi/simple/ 腾讯云 https://mirrors.cloud.tencent.com/pypi/simple/
三、定义了函数来解析每个电影的信息:
设置了请求头部信息,以模拟浏览器的请求,函数返回响应数据的JSON格式内容。
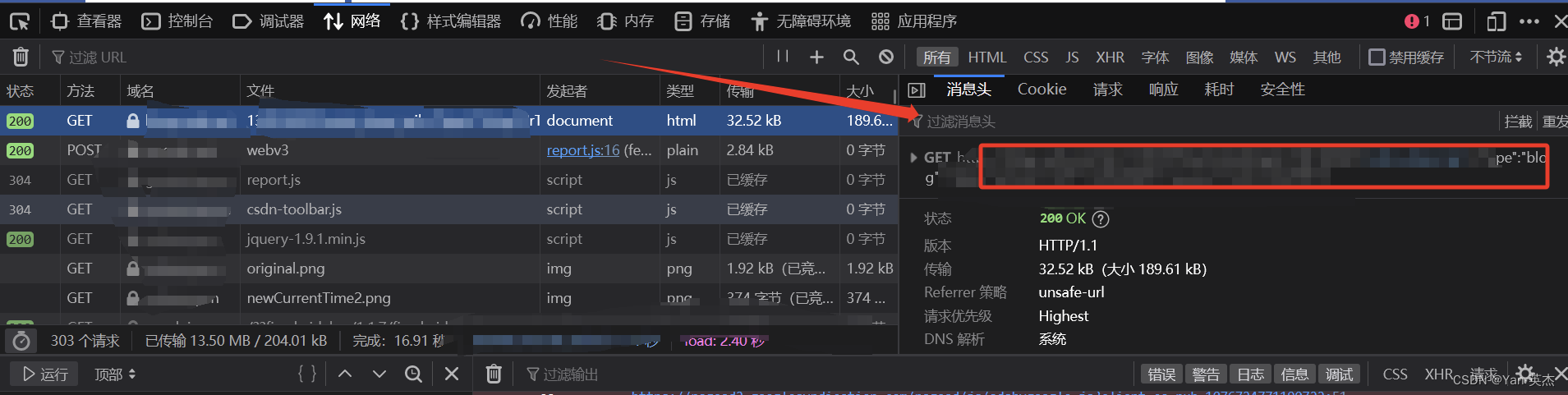
def getSource(url): # 反爬 填写headers请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36' } response = requests.get(url, headers=headers) # 防止出现乱码 response.encoding = 'utf-8' # print(response.text) return response.text如何获取请求头:
火狐浏览器:
(图片来源网络,侵删)- 打开目标网页并右键点击页面空白处。
- 选择“检查元素”选项,或按下快捷键Ctrl + Shift + C(Windows)
- 在开发者工具窗口中,切换到“网络”选项卡。
- 刷新页面以捕获所有的网络请求。
- 在请求列表中选择您感兴趣的请求。
- 在右侧的“请求标头”或“Request Headers”部分,即可找到请求头信息。
将以下请求头信息复制出来即可
四、源代码:
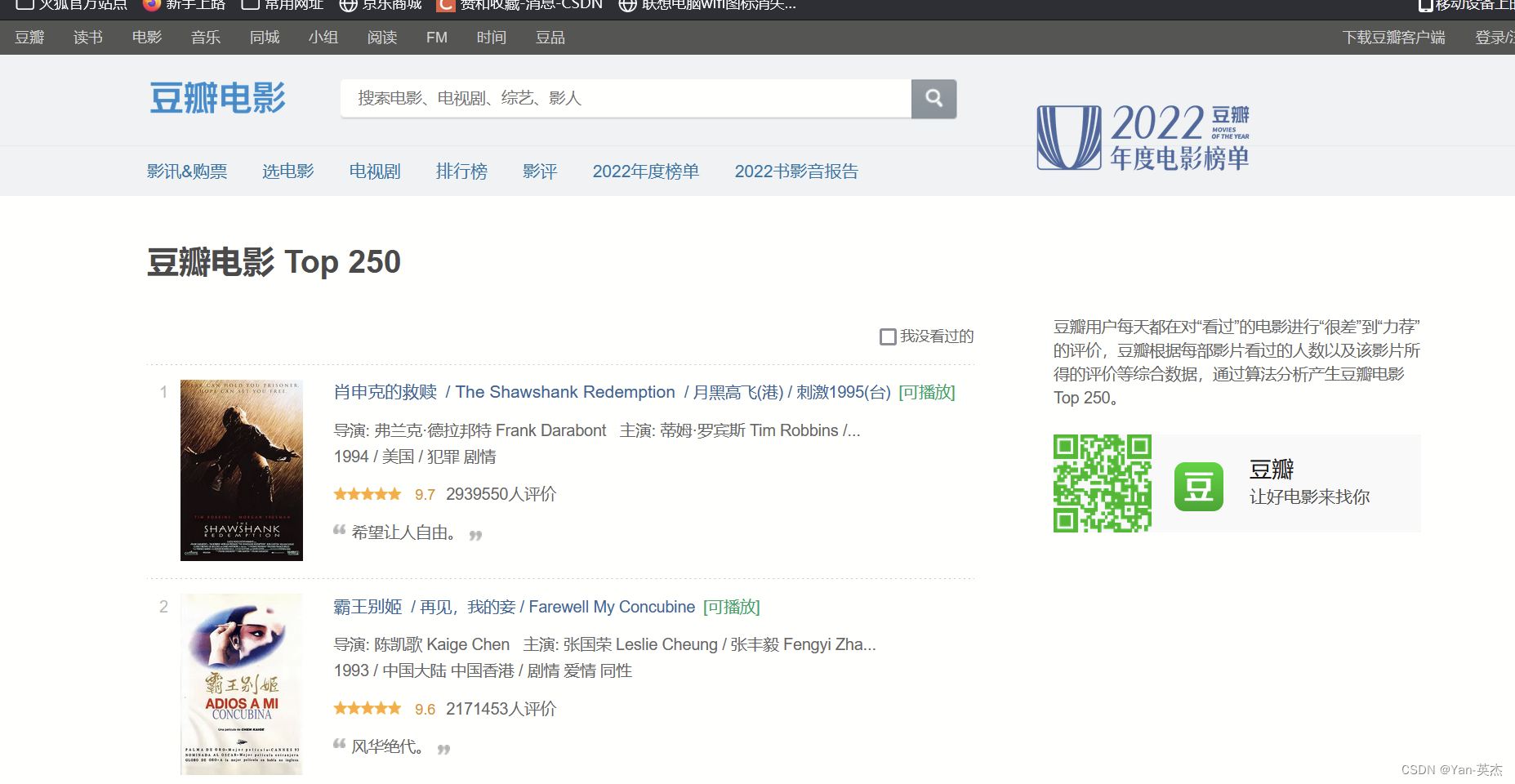
该爬虫程序使用了Python的第三方库BeautifulSoup和正则表达式模块,通过解析HTML页面并进行匹配,提取了电影详情链接、图片链接、影片中文名、影片外国名、评分、评价数、概述以及相关信息等数据,最后将这些数据保存到Excel文件中。
from bs4 import BeautifulSoup import re #正则表达式,进行文字匹配 import urllib.request,urllib.error #指定URL,获取网页数据 import xlwt #进行excel操作 def main(): baseurl = "https://movie.douban.com/top250?start=" datalist= getdata(baseurl) savepath = ".\豆瓣电影top250.xls" savedata(datalist,savepath) #compile返回的是匹配到的模式对象 findLink = re.compile(r'') # 正则表达式模式的匹配,影片详情 findImgSrc = re.compile(r'


文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。
")
")
")
")
还没有评论,来说两句吧...