

数据分析案例-基于亚马逊智能产品评论的探索性数据分析


🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录

一、实验背景
1.1背景概述
1.2实验目的
二、数据描述
2.1数据来源
2.2变量介绍

三、实验步骤
3.1导入模块和数据
3.2数据预处理
3.2.1基本处理
3.3.2数据清洗
3.3探索性数据分析
3.3.1词云图绘制
3.3.2评论极性判断
3.3.3评论可读性
3.3.4评论阅读时间
四、实验总结
源代码
一、实验背景
1.1背景概述
数据成为新时代企业不可或缺的资产,不同行业、不同领域的公司都越来越注重数据在公司运营中发挥的作用,从谷歌、亚马逊到阿里、百度、腾讯,都因其拥有大量的用户注册和运营信息,成为天然的大数据公司。显然亚马逊早已开始尝试从数据中发掘价值,长期以来通过大数据分析,尝试定位客户并获取客户反馈,其不仅从每个用户的购买行为中获得信息,还将每个用户在网站上的所有行为都记录下来,充分体现了亚马逊对数据价值的高度敏感和重视及其强大的挖掘能力。
探索性数据分析(EDA)是指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据结构和规律的一种数据分析方法。是一种分析数据集以概括其主要特征的方法,通常使用可视化技术。完成一个机器学习项目需要有条理的规划方法,无法在收集齐所需要的数据后直接跳到模型搭建的阶段,因此探索性数据分析显得尤为重要。
1.2实验目的
时代与技术的发展使得数据的获取与挖掘成为可能。本实验旨在通过Python对亚马逊的文本数据集进行探索性数据分析,包括产品的评论文本、名称等,使用这些数据进行探索并从中形成见解。
二、数据描述
2.1数据来源
数据来源于Kaggle网站的亚马逊智能产品评论,时间区间为2017年9月至2018年10月,共34656行,21列。部分原始数据如图2-1所示。
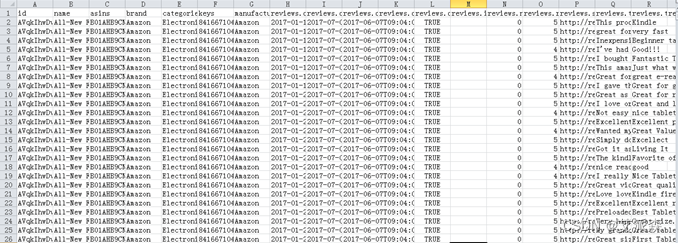
图2-1 亚马逊产品评论数据集原始数据
2.2变量介绍
原始数据集中共包含21个属性,变量说明如表2-1所示。
| 变量名 | 说明 |
| id | 用户编号 |
| name | 产品名称 |
| asins | 产品编号 |
| brand | 品牌 |
| categories | 产品类别 |
| keys | 类别关键字 |
| manufacturer | 制造商 |
| reviews.date | 评论时间 |
| reviews.dateAdded | 追评时间 |
| reviews.dateSeen | 评论可见时间 |
| reviews.didPurchase | 空 |
| reviews.doRecommend | 是否推荐 |
| reviews.id | 评论编号 |
| reviews.numHelpful | 认为评论有用人数 |
| reviews.rating | 评分 |
| reviews.souecrURLs | 评论链接 |
| reviews.text | 评论文本 |
| reviews.title | 评论标题 |
| reviews.userCity | 用户所在地 |
| reviews.userProvince | 用户所在区 |
| reviews.username | 用户名 |
表2-1 亚马逊产品评论数据集字段说明
三、实验步骤
3.1导入模块和数据
在进行探索性数据分析之前需要进行基本的数据预处理,因此首先需要导入相关库并读取数据集。

图3-1 导入实验所需模块并读取数据
如图3-1所示,运行以上代码,若输出结果为“初始数据集大小:(34660,21)”则表示数据导入成功并计算出原始数据集的大小。
3.2数据预处理
3.2.1基本处理
原始数据共包含21个属性,在本实验中主要用到“name、reviews.text、reviews.doRecommend、reviews.numHelpful”等信息,即产品名称、评论文本、是否推荐及认为该评论有用人数。因此对导入数据进行删减,删除其他列,对应的程序及输出结果如图3-2、图3-3所示。

图3-2 删减数据
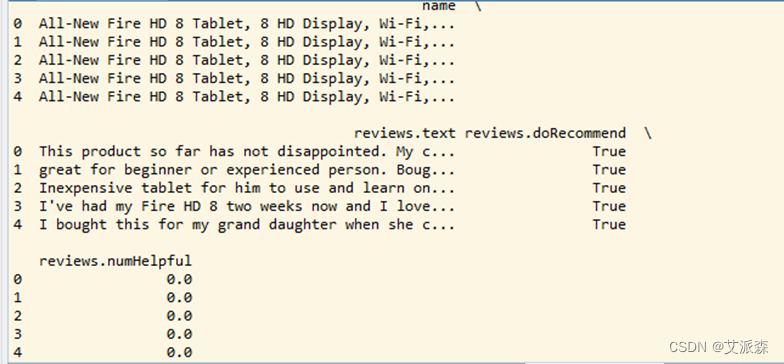
图3-3 删减后的部分数据
删除不必要的列后,通过程序查询是否存在空值并进行删除,同时删除评论数小于500的产品,确保每个产品拥有足够数量的评论数。对应的程序如图3-4所示。

图3-4 处理空值并删除数据
图3-5为处理前后的结果输出,删除后显示数据集中不存在空值,使用lambda函数和filter()过滤数据集,输出结果显示数据集中剩余产品数量为8。
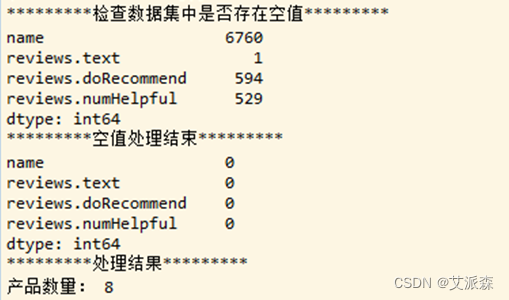
图3-5 处理空值并删除数据
3.3.2数据清洗
文本数据中包含大量的干扰项,如符号、标点符号、停用词等,因此需要对文本进行清洗。
(1)“产品名称”列
首先通过程序查看8种产品的名称,某些产品名称包含由三个连续逗号(,,,)分隔的重复名称。对产品名称做一下文本清洗,其处理过程及处理结果分别如图3-6、图3-7所示:

图3-6 处理“产品名称”列的程序

图3-7 处理前后的“产品名称”列
(2)“评论文本”列
“评论文本”列是后续探索性数据分析的主要对象,因此需要进行细致的处理,在观察数据集中的“评论文本”列后进行处理,主要包括扩展缩略语、改变字母大小写、删除数字及标点、文档术语矩阵创建等步骤。
①扩展缩略语
主要通过创建常用英语缩略语词典的方式将评论中所包含的缩略语映射到对应的扩展形式。
②改变字母大小写
NLP中,即使两个单词相同,但大小写不同,模型也是将其作为不同的单词来处理,因此为方便下一步分析,使用low()函数将文本转换为小写形式。
③删除停用词
借助lambda函数将包括标点符号、数字及包含数字的单词删除。
④创建文档术语矩阵
文档术语矩阵是指一个词在文档集合中出现的频率,在本实验中使用spacy中的函数对每条评论进行停用词删除及词形还原,对每个产品的评论进行汇总,最终生成文档术语矩阵。
相关的程序如图3-8、图3-9所示。
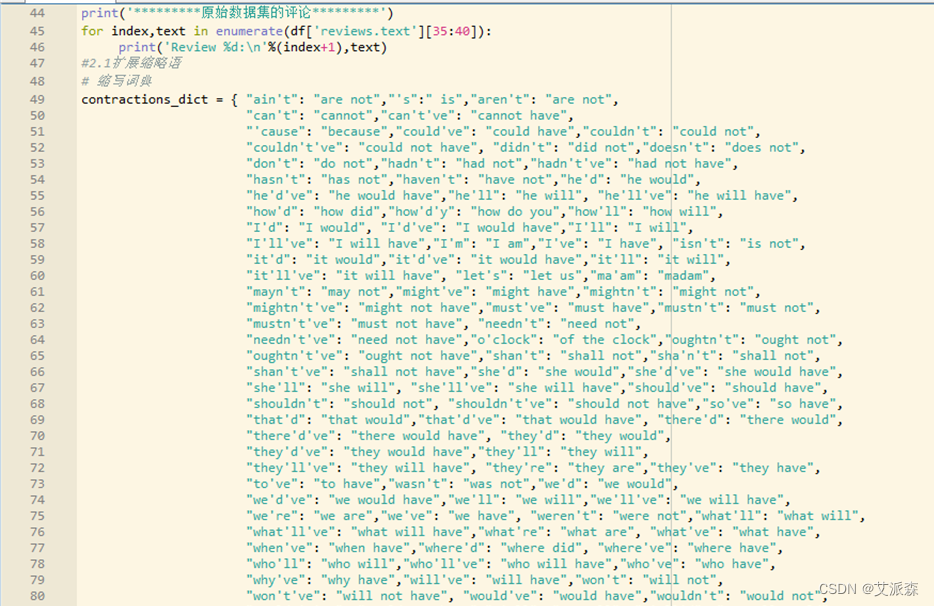
图3-8 “评论文本”列处理程序
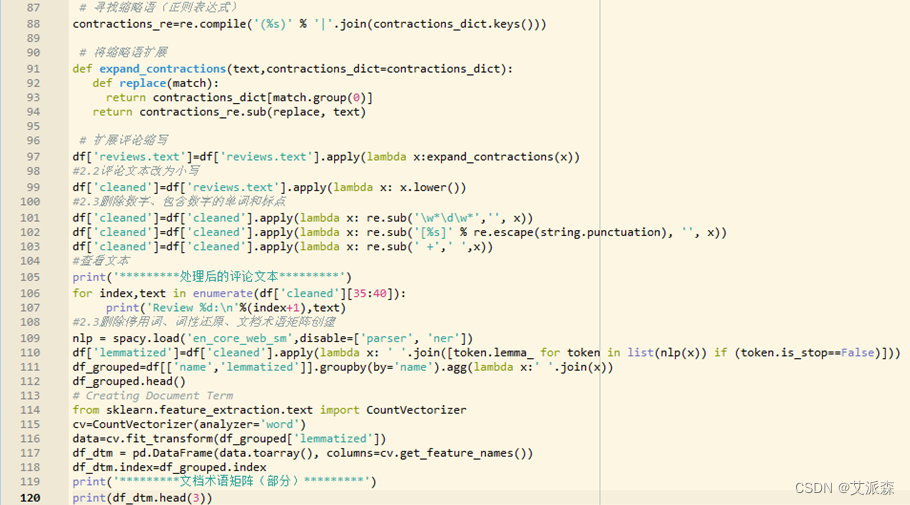
图3-9 “评论文本”列处理程序
输出的结果如图3-10、图3-11所示。

图3-10 处理前后的评论文本

图3-11 生成的文档术语矩阵(部分)
3.3探索性数据分析
完成以上的数据收集及预处理工作后对其进行探索性数据分析。
3.3.1词云图绘制
词云图能够过滤掉大量的文本信息,使用文本中重要的、出现频率较高的词组制图,使得浏览者通过图片就可以得到重要的信息,并从文本信息中快速形成见解。
通过上述处理生成了每种产品的文档术语矩阵,基于此通过词云来可视化这些单词,将频繁出现的单词以更大的尺寸显示出来。其中处理的程序及生成的结果图分别如图3-12、图3-13、图3-14、图3-15、图3-16、图3-17、图3-18、图3-19、图3-20所示。
这8种产品均是从原始数据集中删选出评论>500条的产品,在一定程度上也能说明这8种产品销量高。从生成的词云图中可以看到,大部分产品的高频词汇都有“great”、“good”、“easy”等带有正向情感的单词,这也说明用户对这8种产品总体是呈积极情绪的。
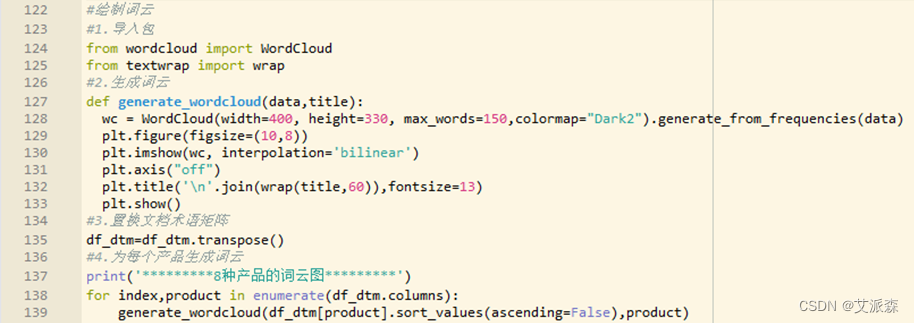
图3-12 生成词云的程序
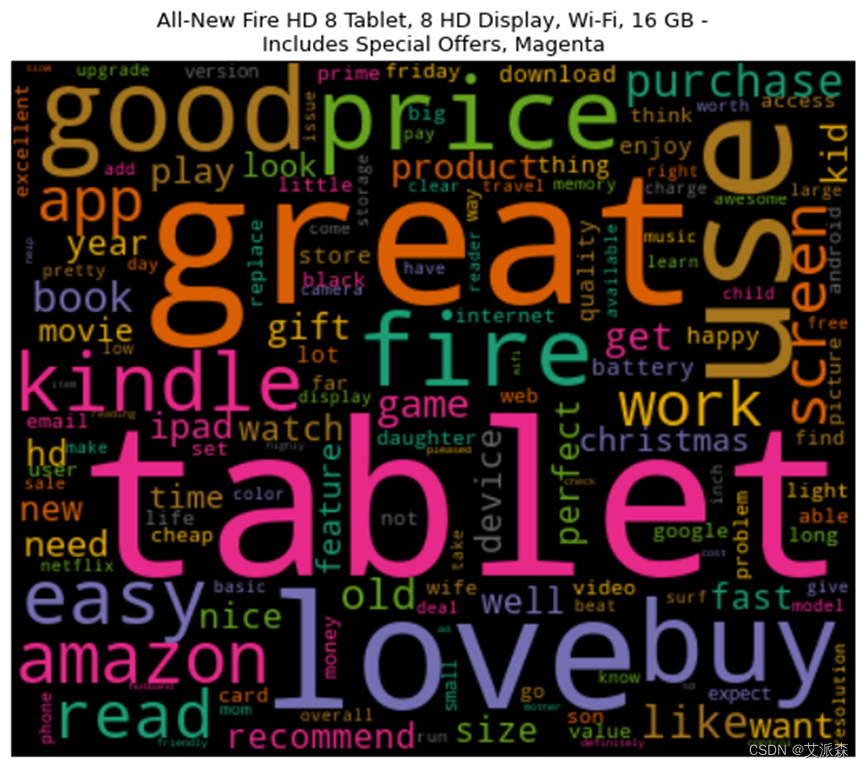
图3-13 产品评论词云图
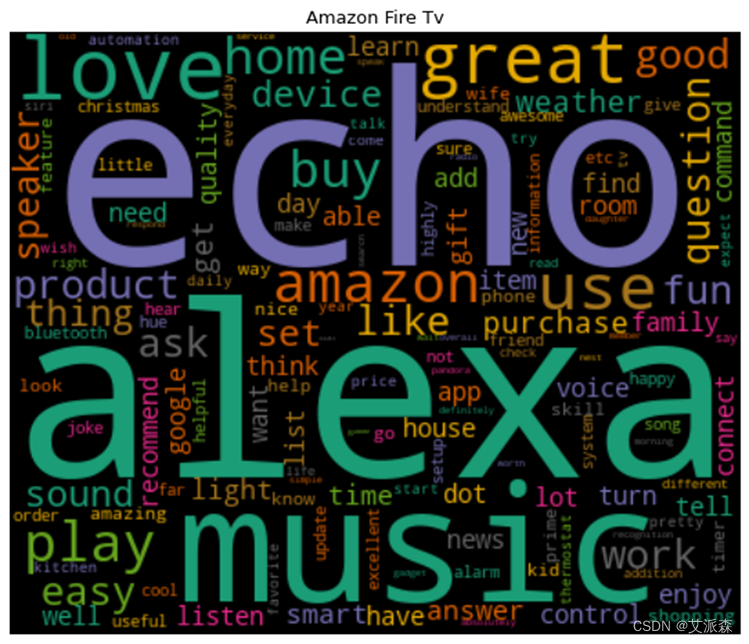
图3-14 产品评论词云图
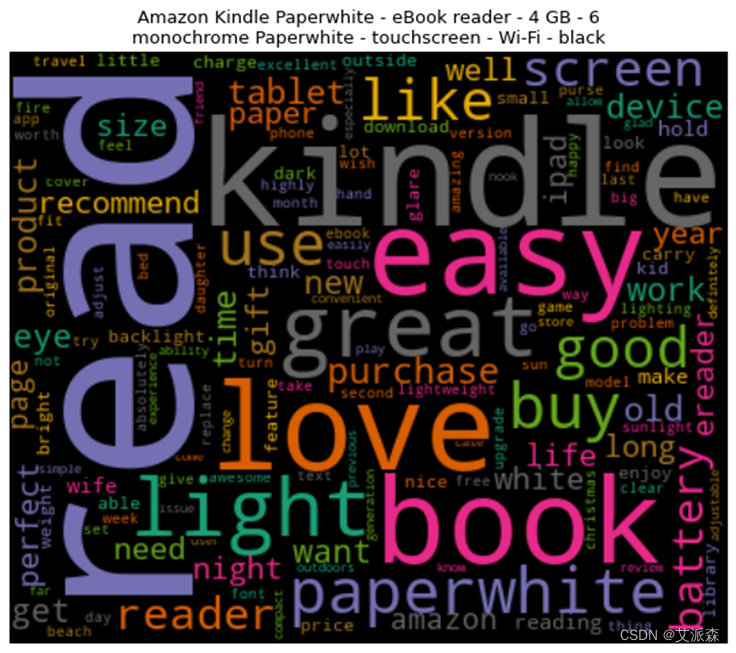
图3-15 产品评论词云图

图3-16 产品评论词云图
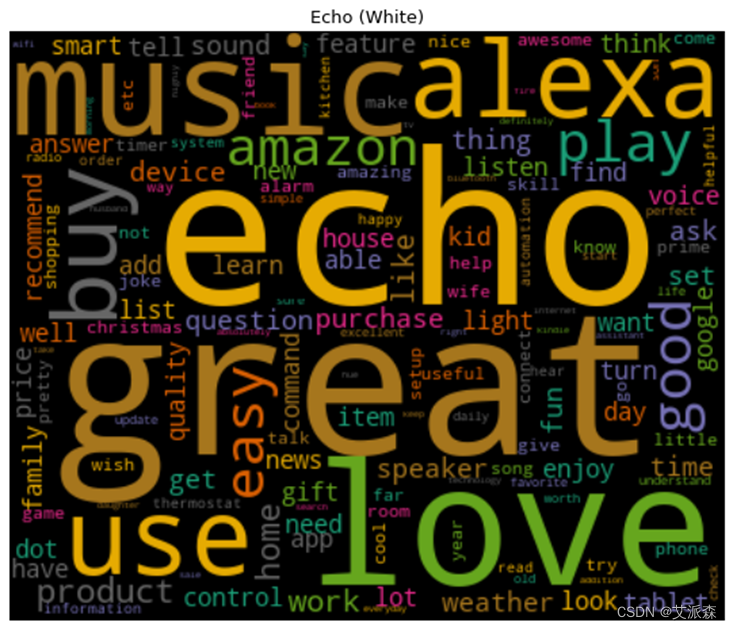
图3-17 产品评论词云图
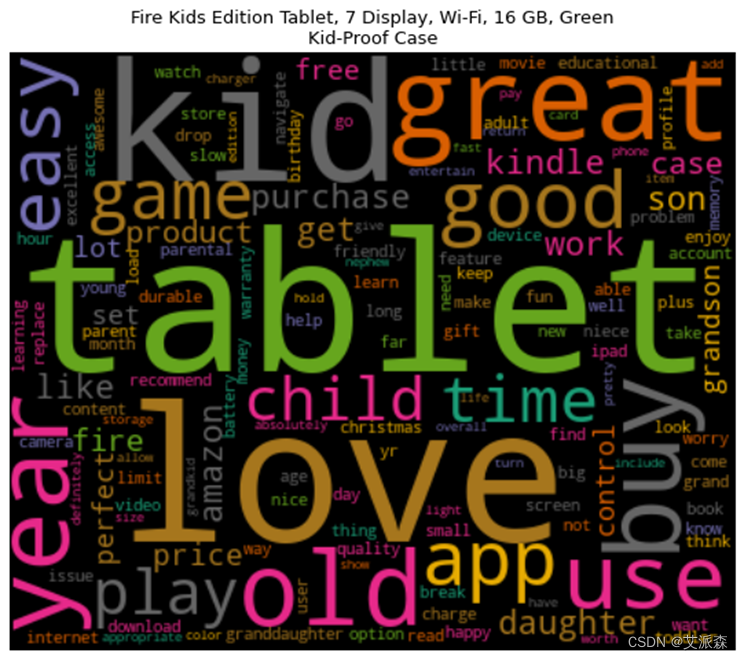
图3-18 产品评论词云图
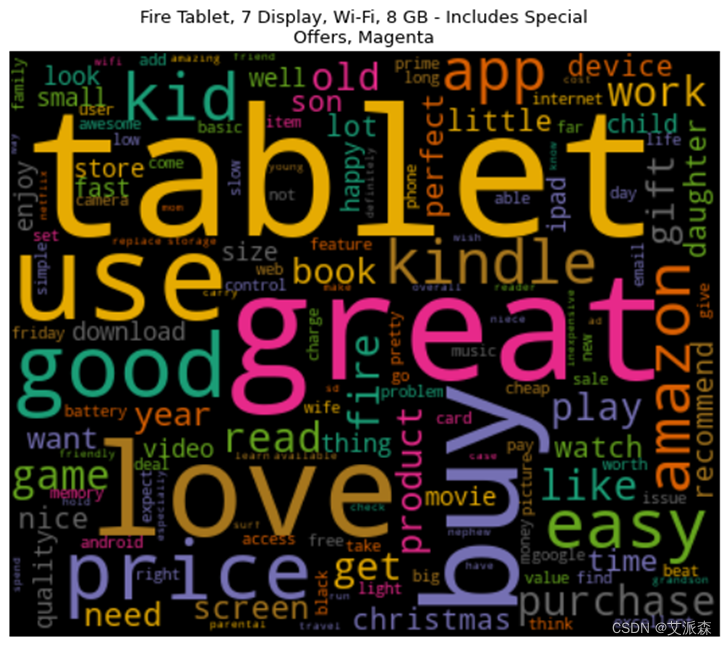
图3-19 产品评论词云图
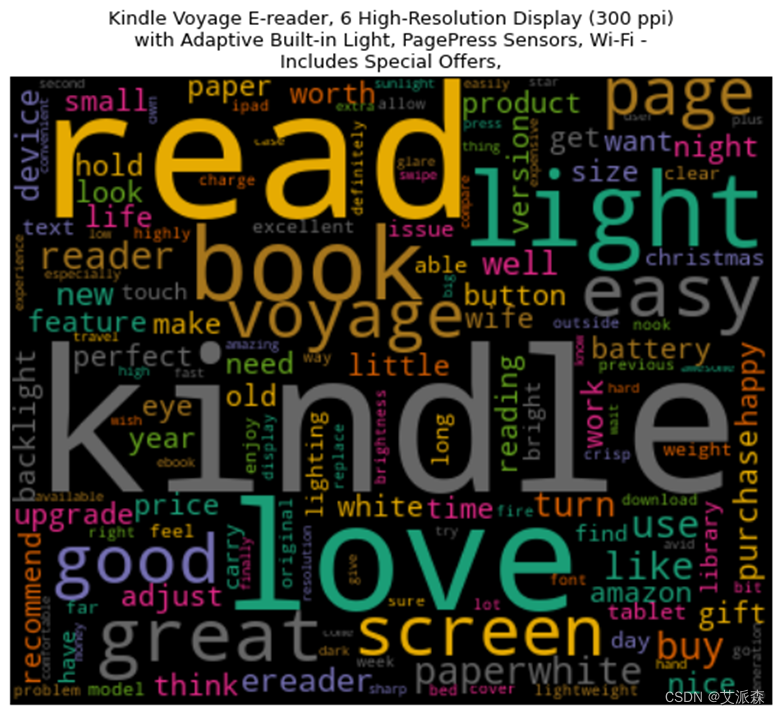
图3-20 产品评论词云图
3.3.2评论极性判断
通过词云图的绘制可以了解消费者对每种产品的情感倾向,但若想进一步研究该问题,了解产品的改进方向,可以对每个产品的评论进行情感分析,通过分析文本是正面或是负面来了解消费者的需求,从而对产品进行改进。通过Python中的TextBlob库来检查评论的极性,并通过条形图的绘制对每个产品的极性进行比较。其中处理的程序及生成的结果图分别如图3-21、图3-22、图3-23、图3-14所示。
图3-21和图3-22分别表示对评论文本进行极性判断的程序与结果,polarity的分数是一个范围为 [-1.0 , 1.0 ] 浮点数, 正数表示积极,负数表示消极。通过结果可以看出,在这8种产品中Fire Kids Edition Tablet和Kindle Voyage E-reader两款产品的数值偏低,因此可以针对这两种产品进行进一步的分析,以更好地了解消费者的需求。

图3-21 产品评论极性判断程序
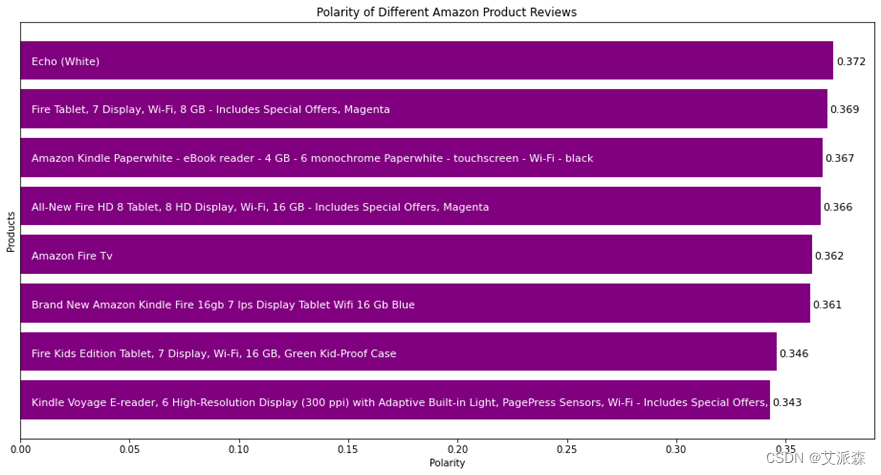
图3-22 产品评论极性条形图
数据集中的“reviews.doRecommend”属性表示消费者是否推荐购买该产品,有True、Flase两个值,True表示推荐购买,Flase表示不推荐购买,通过了解购买某一产品的消费者是否推荐购买该产品也可了解消费者对该商品的情感趋势。以推荐购买某产品的消费者百分比作为横轴绘制条形图,其程序和结果如图3-23、图3-24所示。可以看到产品 Fire Kids Edition Tablet 的推荐比例最低,它的评论也较负面。
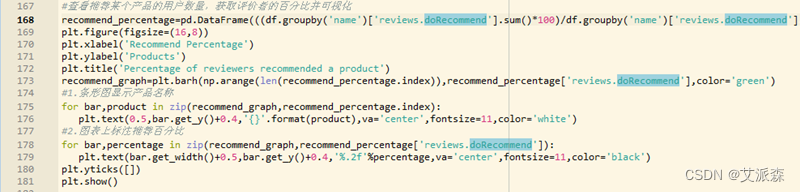
图3-23 产品推荐情况程序

图3-24 产品推荐情况
3.3.3评论可读性
Textstat是一个可以计算英文可阅读性的python包,通常用于判断特定语料库的可读性与复杂性,内置有Flesch阅读容易度、Dale Chall可读性评分和Gunning Fog指数。每个指标使用不同的方法确定文档的可读性级别。
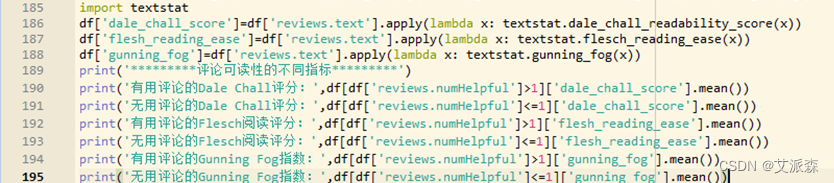
图3-25 产品评论可读性程序

图3-26 产品评论可读性结果
3.3.4评论阅读时间
数据集中的“reviews.numHelpful”属性表示消费者认为该评论是否有帮助,若该数字大于等于1,则表示该评论对消费者有所帮助,若该数字小于1,则表示该评论对消费者暂无帮助。textstat库中的reading_time()函数将某段文本作为参考,以秒为单位返回该文本的阅读时间,调用该函数分别计算有用评论与无用评论的阅读时间。结果显示有用评论的阅读时间是无用评论阅读时间的将近两倍,这从侧面说明了较长的评论对消费者更有帮助。相关程序及结果如图3-27、图3-28所示。

图3-27 评论阅读时间

图3-28 评论阅读时间结果
四、实验总结
通过此次实验,对Python、EDA、自然语言处理有了进一步的了解。本实验主题为“基于评论的探索性数据分析”,主要针对亚马逊网站部分产品的相关文本信息,如评论文本、是否被推荐等属性进行探索性数据分析。在对数据进行基本的处理及必要的清洗后,从词云绘制、评论极性判断、评论可阅读性、评论阅读时间等角度为出发点进行探索。主要得出以下推论:
(1)在数据集所涉及评论数较多的产品中,消费者总体呈满意态度;
(2)Fire Kids Edition Tablet 属于本数据集中负面评论较多且最不被推荐的产品,可针对这款产品进行进一步分析,了解其不足之处并明确完善方向;
(3)有用评论的阅读时间高于非有用评论,这意味着人们认为较长的评论更具有帮助性。
源代码
import numpy as np
import pandas as pd
# 可视化
import matplotlib.pyplot as plt
# 正则化
import re
# 处理字符串
import string
# 执行数学运算
import spacy
# 导入数据并进行基本的预处理
df=pd.read_csv('dataset.csv',low_memory=False)
print("初始数据集大小:",df.shape)
#1.删除不必要的列
df=df[['name','reviews.text','reviews.doRecommend','reviews.numHelpful']]
print("数据集大小:",df.shape)
print('*********处理后的部分数据*********')
pd.set_option('display.max_columns', None)
print(df.head(5))
#2.删除空值
print('*********检查数据集中是否存在空值*********')
print(df.isnull().sum())
df.dropna(inplace=True)
print('*********空值处理结束*********')
print(df.isnull().sum())
#3.删除评论数500).reset_index(drop=True)
print('*********处理结果*********')
print('产品数量:',len(df['name'].unique()))
#4.将不能直接处理的数据类型转换为整形
df['reviews.doRecommend']=df['reviews.doRecommend'].astype(int)
df['reviews.numHelpful']=df['reviews.numHelpful'].astype(int)
# 清洗文本数据
#1.处理产品名称
print('*********产品名称*********')
print(df['name'].unique())
df['name']=df['name'].apply(lambda x: x.split(',,,')[0])
print('*********处理后的产品名称*********')
print(df['name'].unique())
#2.处理评论文本
print('*********原始数据集的评论*********')
for index,text in enumerate(df['reviews.text'][35:40]):
print('Review %d:\n'%(index+1),text)
#2.1扩展缩略语
# 缩写词典
contractions_dict = { "ain't": "are not","'s":" is","aren't": "are not",
"can't": "cannot","can't've": "cannot have",
"'cause": "because","could've": "could have","couldn't": "could not",
"couldn't've": "could not have", "didn't": "did not","doesn't": "does not",
"don't": "do not","hadn't": "had not","hadn't've": "had not have",
"hasn't": "has not","haven't": "have not","he'd": "he would",
"he'd've": "he would have","he'll": "he will", "he'll've": "he will have",
"how'd": "how did","how'd'y": "how do you","how'll": "how will",
"I'd": "I would", "I'd've": "I would have","I'll": "I will",
"I'll've": "I will have","I'm": "I am","I've": "I have", "isn't": "is not",
"it'd": "it would","it'd've": "it would have","it'll": "it will",
"it'll've": "it will have", "let's": "let us","ma'am": "madam",
"mayn't": "may not","might've": "might have","mightn't": "might not",
"mightn't've": "might not have","must've": "must have","mustn't": "must not",
"mustn't've": "must not have", "needn't": "need not",
"needn't've": "need not have","o'clock": "of the clock","oughtn't": "ought not",
"oughtn't've": "ought not have","shan't": "shall not","sha'n't": "shall not",
"shan't've": "shall not have","she'd": "she would","she'd've": "she would have",
"she'll": "she will", "she'll've": "she will have","should've": "should have",
"shouldn't": "should not", "shouldn't've": "should not have","so've": "so have",
"that'd": "that would","that'd've": "that would have", "there'd": "there would",
"there'd've": "there would have", "they'd": "they would",
"they'd've": "they would have","they'll": "they will",
"they'll've": "they will have", "they're": "they are","they've": "they have",
"to've": "to have","wasn't": "was not","we'd": "we would",
"we'd've": "we would have","we'll": "we will","we'll've": "we will have",
"we're": "we are","we've": "we have", "weren't": "were not","what'll": "what will",
"what'll've": "what will have","what're": "what are", "what've": "what have",
"when've": "when have","where'd": "where did", "where've": "where have",
"who'll": "who will","who'll've": "who will have","who've": "who have",
"why've": "why have","will've": "will have","won't": "will not",
"won't've": "will not have", "would've": "would have","wouldn't": "would not",
"wouldn't've": "would not have","y'all": "you all", "y'all'd": "you all would",
"y'all'd've": "you all would have","y'all're": "you all are",
"y'all've": "you all have", "you'd": "you would","you'd've": "you would have",
"you'll": "you will","you'll've": "you will have", "you're": "you are",
"you've": "you have"}
# 寻找缩略语(正则表达式)
contractions_re=re.compile('(%s)' % '|'.join(contractions_dict.keys()))
# 将缩略语扩展
def expand_contractions(text,contractions_dict=contractions_dict):
def replace(match):
return contractions_dict[match.group(0)]
return contractions_re.sub(replace, text)
# 扩展评论缩写
df['reviews.text']=df['reviews.text'].apply(lambda x:expand_contractions(x))
#2.2评论文本改为小写
df['cleaned']=df['reviews.text'].apply(lambda x: x.lower())
#2.3删除数字、包含数字的单词和标点
df['cleaned']=df['cleaned'].apply(lambda x: re.sub('\w*\d\w*','', x))
df['cleaned']=df['cleaned'].apply(lambda x: re.sub('[%s]' % re.escape(string.punctuation), '', x))
df['cleaned']=df['cleaned'].apply(lambda x: re.sub(' +',' ',x))
#查看文本
print('*********处理后的评论文本*********')
for index,text in enumerate(df['cleaned'][35:40]):
print('Review %d:\n'%(index+1),text)
#2.3删除停用词、词性还原、文档术语矩阵创建
nlp = spacy.load('en_core_web_sm',disable=['parser', 'ner'])
df['lemmatized']=df['cleaned'].apply(lambda x: ' '.join([token.lemma_ for token in list(nlp(x)) if (token.is_stop==False)]))
df_grouped=df[['name','lemmatized']].groupby(by='name').agg(lambda x:' '.join(x))
df_grouped.head()
# Creating Document Term
from sklearn.feature_extraction.text import CountVectorizer
cv=CountVectorizer(analyzer='word')
data=cv.fit_transform(df_grouped['lemmatized'])
df_dtm = pd.DataFrame(data.toarray(), columns=cv.get_feature_names())
df_dtm.index=df_grouped.index
print('*********文档术语矩阵(部分)*********')
print(df_dtm.head(3))
#绘制词云
#1.导入包
from wordcloud import WordCloud
from textwrap import wrap
#2.生成词云
def generate_wordcloud(data,title):
wc = WordCloud(width=400, height=330, max_words=150,colormap="Dark2").generate_from_frequencies(data)
plt.figure(figsize=(10,8))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.title('\n'.join(wrap(title,60)),fontsize=13)
plt.show()
#3.置换文档术语矩阵
df_dtm=df_dtm.transpose()
#4.为每个产品生成词云
print('*********8种产品的词云图*********')
for index,product in enumerate(df_dtm.columns):
generate_wordcloud(df_dtm[product].sort_values(ascending=False),product)
#检查评论极性(TextBlob是一个用Python编写的开源的文本处理库。 它可以用来执行很多自然语言处理的任务,比如,词性标注,名词性成分提取,情感分析,文本翻译,等等。)
from textblob import TextBlob
df['polarity']=df['lemmatized'].apply(lambda x:TextBlob(x).sentiment.polarity)
#1.查看最消极、积极的评价
print('*********3条随机的积极评论*********')
for index,review in enumerate(df.iloc[df['polarity'].sort_values(ascending=False)[:3].index]['reviews.text']):
print('Review {}:\n'.format(index+1),review)
print('*********3条随机的消极评论*********')
for index,review in enumerate(df.iloc[df['polarity'].sort_values(ascending=True)[:3].index]['reviews.text']):
print('Review {}:\n'.format(index+1),review)
#2.画出每个产品的评论的极性并进行比较
product_polarity_sorted=pd.DataFrame(df.groupby('name')['polarity'].mean().sort_values(ascending=True))
plt.figure(figsize=(16,8))
plt.xlabel('Polarity')
plt.ylabel('Products')
plt.title('Polarity of Different Amazon Product Reviews')
polarity_graph=plt.barh(np.arange(len(product_polarity_sorted.index)),product_polarity_sorted['polarity'],color='purple',)
#条形图显示产品名称
for bar,product in zip(polarity_graph,product_polarity_sorted.index):
plt.text(0.005,bar.get_y()+bar.get_width(),'{}'.format(product),va='center',fontsize=11,color='white')
#图上标注极性值
for bar,polarity in zip(polarity_graph,product_polarity_sorted['polarity']):
plt.text(bar.get_width()+0.001,bar.get_y()+bar.get_width(),'%.3f'%polarity,va='center',fontsize=11,color='black')
plt.yticks([])
plt.show()
#查看推荐某个产品的用户数量,获取评价者的百分比并可视化
recommend_percentage=pd.DataFrame(((df.groupby('name')['reviews.doRecommend'].sum()*100)/df.groupby('name')['reviews.doRecommend'].count()).sort_values(ascending=True))
plt.figure(figsize=(16,8))
plt.xlabel('Recommend Percentage')
plt.ylabel('Products')
plt.title('Percentage of reviewers recommended a product')
recommend_graph=plt.barh(np.arange(len(recommend_percentage.index)),recommend_percentage['reviews.doRecommend'],color='green')
#1.条形图显示产品名称
for bar,product in zip(recommend_graph,recommend_percentage.index):
plt.text(0.5,bar.get_y()+0.4,'{}'.format(product),va='center',fontsize=11,color='white')
#2.图表上标注推荐百分比
for bar,percentage in zip(recommend_graph,recommend_percentage['reviews.doRecommend']):
plt.text(bar.get_width()+0.5,bar.get_y()+0.4,'%.2f'%percentage,va='center',fontsize=11,color='black')
plt.yticks([])
plt.show()
#查看评论可读性
recommend_percentage=pd.DataFrame(((df.groupby('name')['reviews.doRecommend'].sum()*100)/df.groupby('name')['reviews.doRecommend'].count()).sort_values(ascending=True))
import textstat
df['dale_chall_score']=df['reviews.text'].apply(lambda x: textstat.dale_chall_readability_score(x))
df['flesh_reading_ease']=df['reviews.text'].apply(lambda x: textstat.flesch_reading_ease(x))
df['gunning_fog']=df['reviews.text'].apply(lambda x: textstat.gunning_fog(x))
print('*********评论可读性的不同指标*********')
print('有用评论的Dale Chall评分:',df[df['reviews.numHelpful']>1]['dale_chall_score'].mean())
print('无用评论的Dale Chall评分:',df[df['reviews.numHelpful']1]['flesh_reading_ease'].mean())
print('无用评论的Flesch阅读评分:',df[df['reviews.numHelpful']1]['gunning_fog'].mean())
print('无用评论的Gunning Fog指数:',df[df['reviews.numHelpful']1]['reading_time'].mean())
print('无用评论的阅读时间:',df[df['reviews.numHelpful']")
")
")
")
还没有评论,来说两句吧...