

lxml&xpath一站式教学
文章目录
- XPath定义
- XPath 概览
- 安装lxml
- 初步使用
- xpath 常用表达式
- 获取所有节点
- 获取子节点
- 获取父亲节点
- 属性匹配
- 获取文本
- 获取属性
- 属性多值匹配
- 多属性匹配
- 按序选择
- 节点轴选择
- 总结
XPath定义
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。它最初是用来搜寻 XML 文档的,现在它同样适用于 HTML 文档的搜索
(图片来源网络,侵删)XPath 概览
XPath 的选择功能十分强大,它提供了非常简洁明了的路径选择表达式 。 另外,它还提供了超过100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等 。 几乎所有我们想要定位的节点,都可以用 XPath 来选择 。
安装lxml
pip install lxml
初步使用
读取本地html文件
etree模块会自动修正HTML文件中缺失的内容
from lxml import etree # 读取html文档,字符串 fp = open("index.html",'r',encoding='utf-8') html = fp.read() # 实例化XPath解析对象,可以将字符串转换成Element对象 tree = etree.HTML(html) print(tree)web网站html文件
from lxml import etree import requests html = requests.get(url="https://www.baidu.com") tree = etree.HTML(html.text) print(tree)
xpath 常用表达式
xpath的使用其实就是根据表达式找出文档中所有符合条件的内容
表达式 描述 nodename 选取此节点的所有子节点 / 从当前节点选取直接子节点 // 从当前节点选取子孙节点 . 选取当前节点 .. 选取当前节点的父节点 @ 选取属性 * 通配符,选择所有元素节点与元素名 [@attrib] 选取具有给定属性的所有元素 [@attrib=‘value’] 选取给定属性具有给定值的所有元素 [tag] 选取所有具有指定元素的直接子节点 [tag=‘text’] 选取所有具有指定元素并且文本内容是text节点 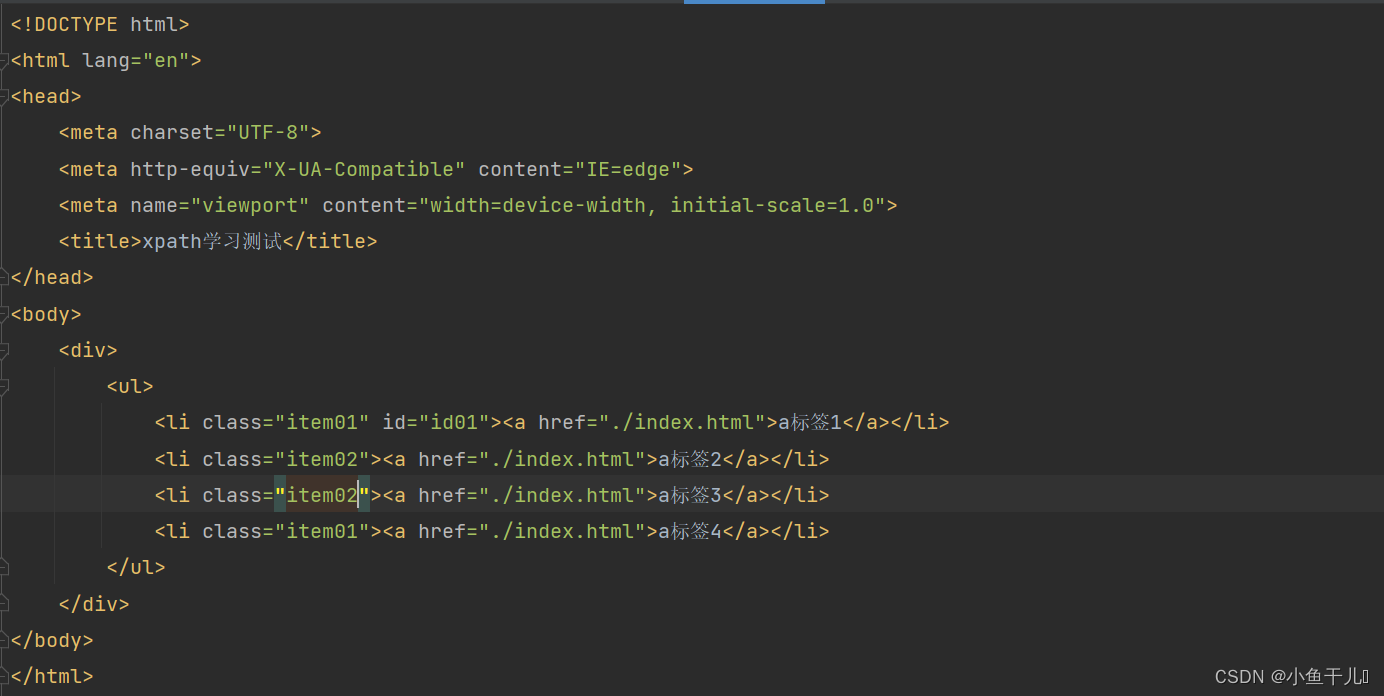 (图片来源网络,侵删)
(图片来源网络,侵删)获取所有节点
fp = open("index.html",'r',encoding='utf-8') html = fp.read() tree = etree.HTML(html) result = tree.xpath("//*") # 获取所有节点 print(result)输入:

解释:
// 获取当前节点的子孙节点 * 代表匹配所有节点,//* 就代表获取当前节点的所有子孙节点
获取子孙节点中的div节点
# 获取当前节点下的所有div的子孙节点 result = tree.xpath("//div")输出:

获取子节点
现在要获取下的head节点以及head节点里面的title节点
result = tree.xpath("/html/head") # 获取head节点 print(result) result = tree.xpath("/html/head/title") # 获取title节点 print(result)输出:

解释:这里我们采用的是 /来进行获取的,每次获取一级,依次获取到目标元素
获取父亲节点
通过 / 、//可以获取子节点或者子孙节点,现在我学习如何通过子节点找父节点
找出li节点的父节点,找出li节点的父节点的父亲节点
result = tree.xpath("//li/..") print(result) result = tree.xpath("//li/../..") print(result)输出:

通过输出我们可以看到li的父节点是ul, ul的父节点是div
解释:
先通过 //li找到li节点在通过 .. 找到父节点
属性匹配
找出li标签中class=item01的元素
result = tree.xpath('/html/body/div/ul/li[@]') print(result)输出:

选择属性中有id的
result = tree.xpath('/html/body/div/ul/li[@id]') print(result)输出:

解释:
通过@ 我们可以根据属性寻找节点,可以指定属性值,也可以直接根据属性进行查询
获取文本
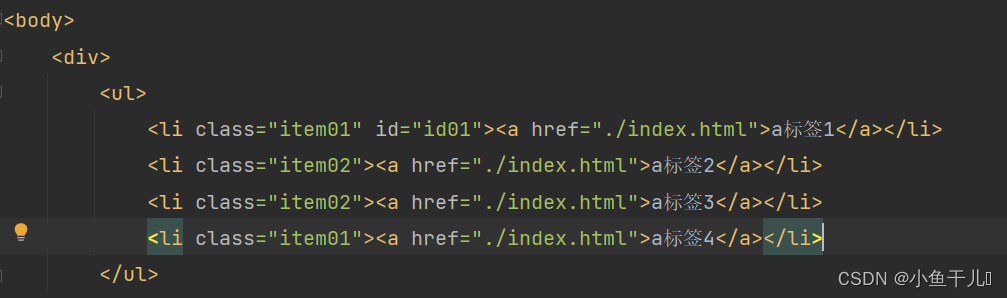
获取li中的文字
# 直接获取li标签下面所有子孙元素的文字 result = tree.xpath('/html/body/div/ul/li//text()') print(result) # 通过寻找子元素的方式,一级一级的找到文字 result2 = tree.xpath('/html/body/div/ul/li/a/text()') print(result2)输出:

通过输出的内容分析我们能够看出,直接通过li//text()获取到文本内容会比li/a/text()获取的多,因为li//text()或获取li中所有的文字包括换行,而li/a/text()只会找出a标签下所有的文字
获取属性
有时候我们在进行数据解析的时候会需要一些属性值,例如我们在写爬虫项目的时候我们往往需要url链接
找出li中id=id01 a标签中 href的值
result = tree.xpath('/html/body/div/ul/li[@id="id01"]/a/@href') print(result)输出

解释:
属性值的获取也是通过@ 来进行实现的,@href:获取href的属性值
属性多值匹配
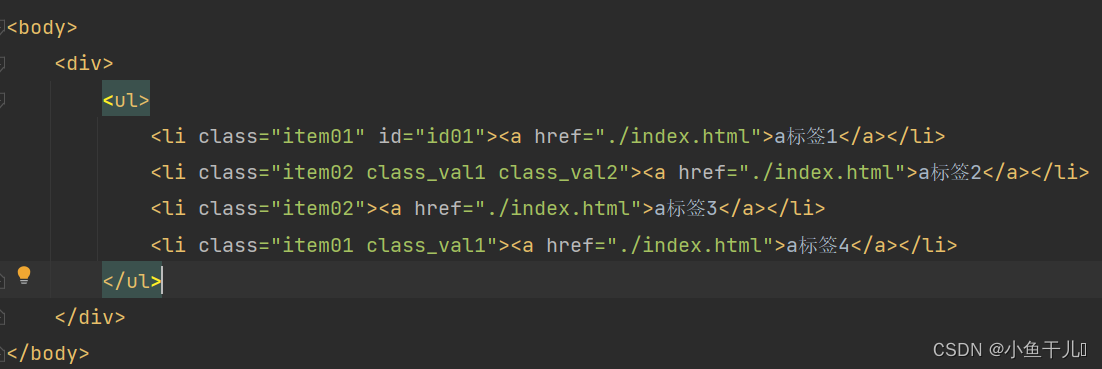
在实际的项目中会出现一个属性值有多个值的情况出现,例如class在实际项目中会有多个值的情况出现
获取class中含有class_val1的节点
# 这种方式是错误的,并不会找出对应的class中含有class_val1的节点 tree.xpath('/html/body/div/ul/li[@]') # 正确的做法 使用contains()函数 # 获取class中含有class_val1的节点 result = tree.xpath('/html/body/div/ul/li[contains(@class,"class_val1")]') print(result)输出:

解释:
contains()函数 获取指定属性中包含某一属性值的节点
使用方式contains(@属性,"属性值")
多属性匹配
有时候我还需要根据多个属性来确定一个节点
找出li中 class中含有item01且id=id01 中a标签中的文本
result = tree.xpath('/html/body/div/ul/li[contains(@class,"item01") and @id="id01"]/a/text()') print(result)
解释:
使用 and可以连接多个条件值
拓展类似的操作符还有
运算符 描述 实例 返回值 or 或 age=10 or age=20 如果age等于10或者等于20则返回true反正返回false and 与 age>19 and age


")
")
")
还没有评论,来说两句吧...