

100天精通Python(实用脚本篇)——第117天:基于selenium实现反反爬策略之代码输入账号信息登录网站
文章目录
- 专栏导读
- 1. 前言
- 2. 实现步骤
- 3. 基础补充
- 4. 代码实战
- 4.1 创建连接
- 4.2 添加请求头伪装浏览器
- 4.3 隐藏浏览器指纹
- 4.4 最大化窗口
- 4.5 启动网页
- 4.6 点击密码登录
- 4.7 输入账号密码
- 4.8 点击登录按钮
- 4.9 完整代码
- 4.10 GIF动图展示
- 五、总结
专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
(图片来源网络,侵删)- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
1. 前言
上文我们学习了通过cookie登录网站,接下来我们来学用代码输入账号信息登录网,测试网站某宝。
2. 实现步骤
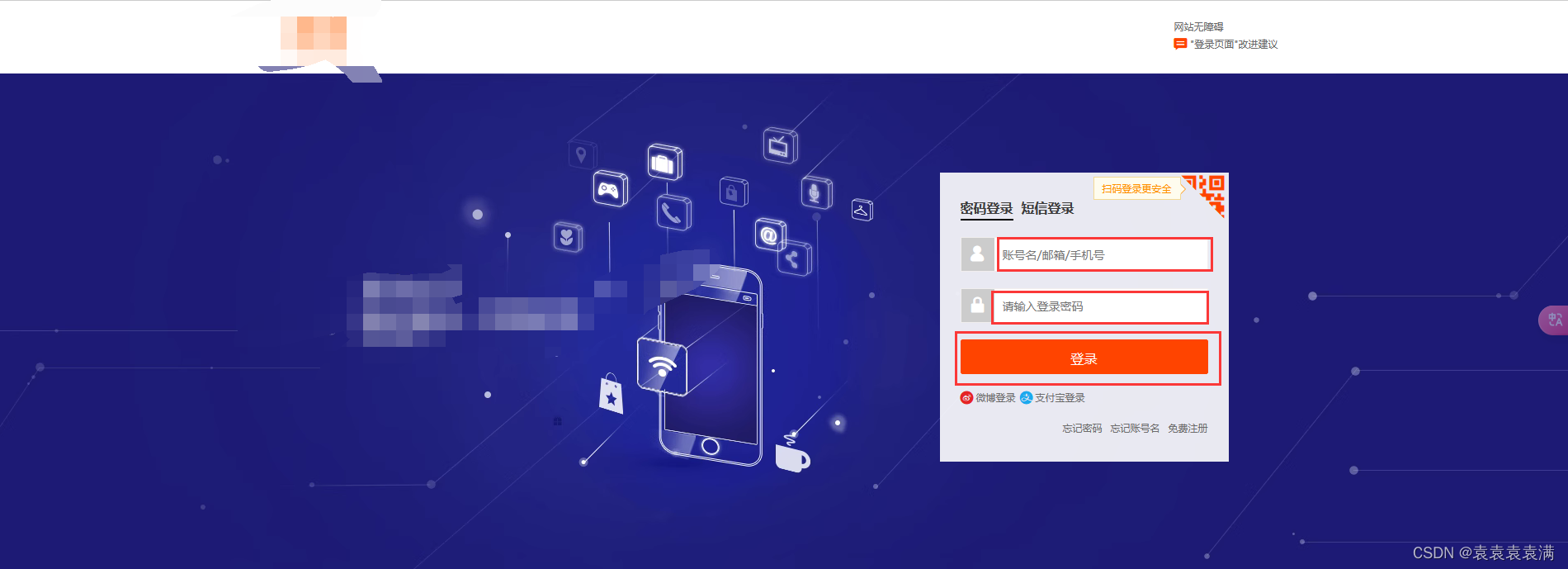
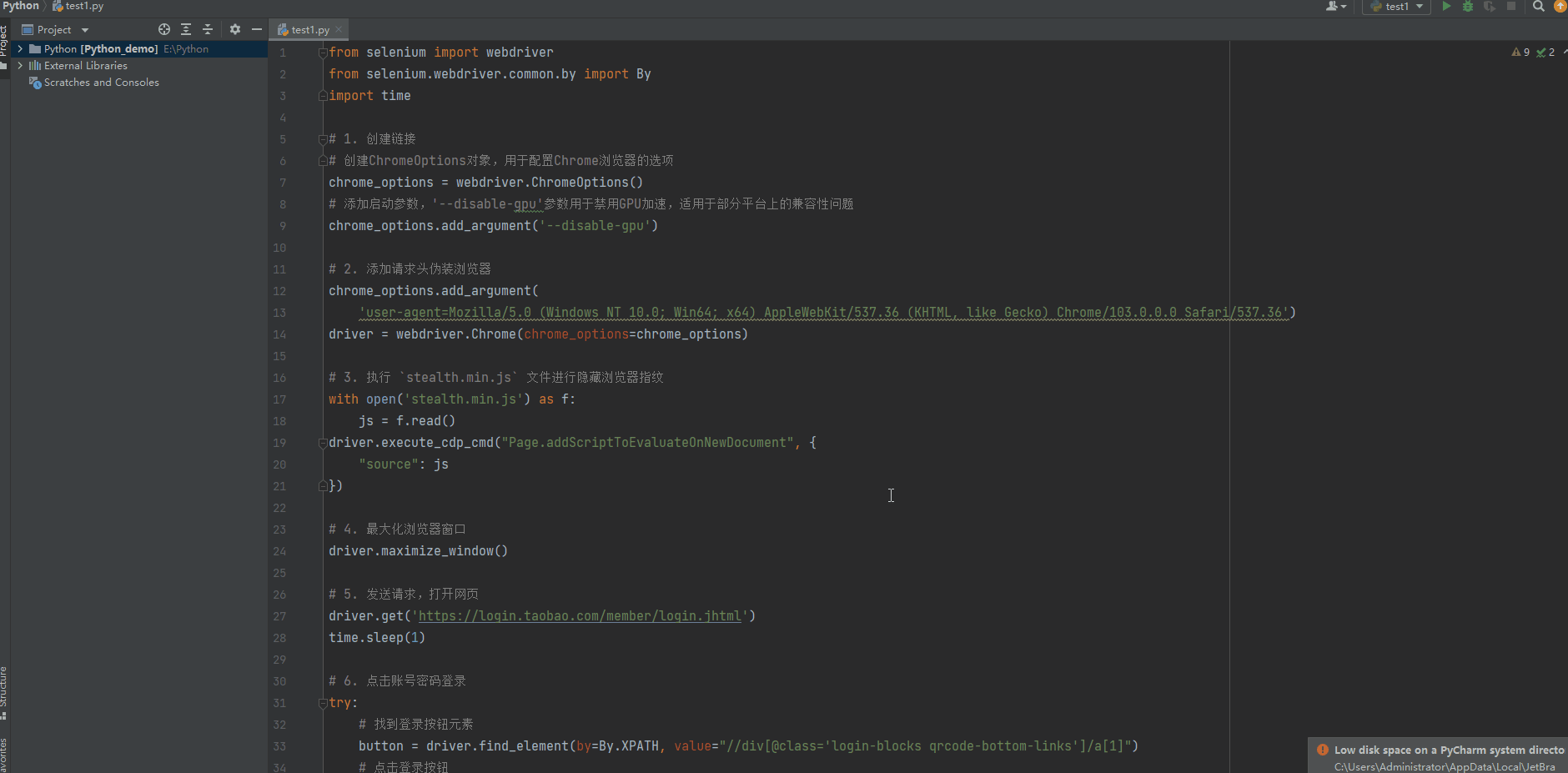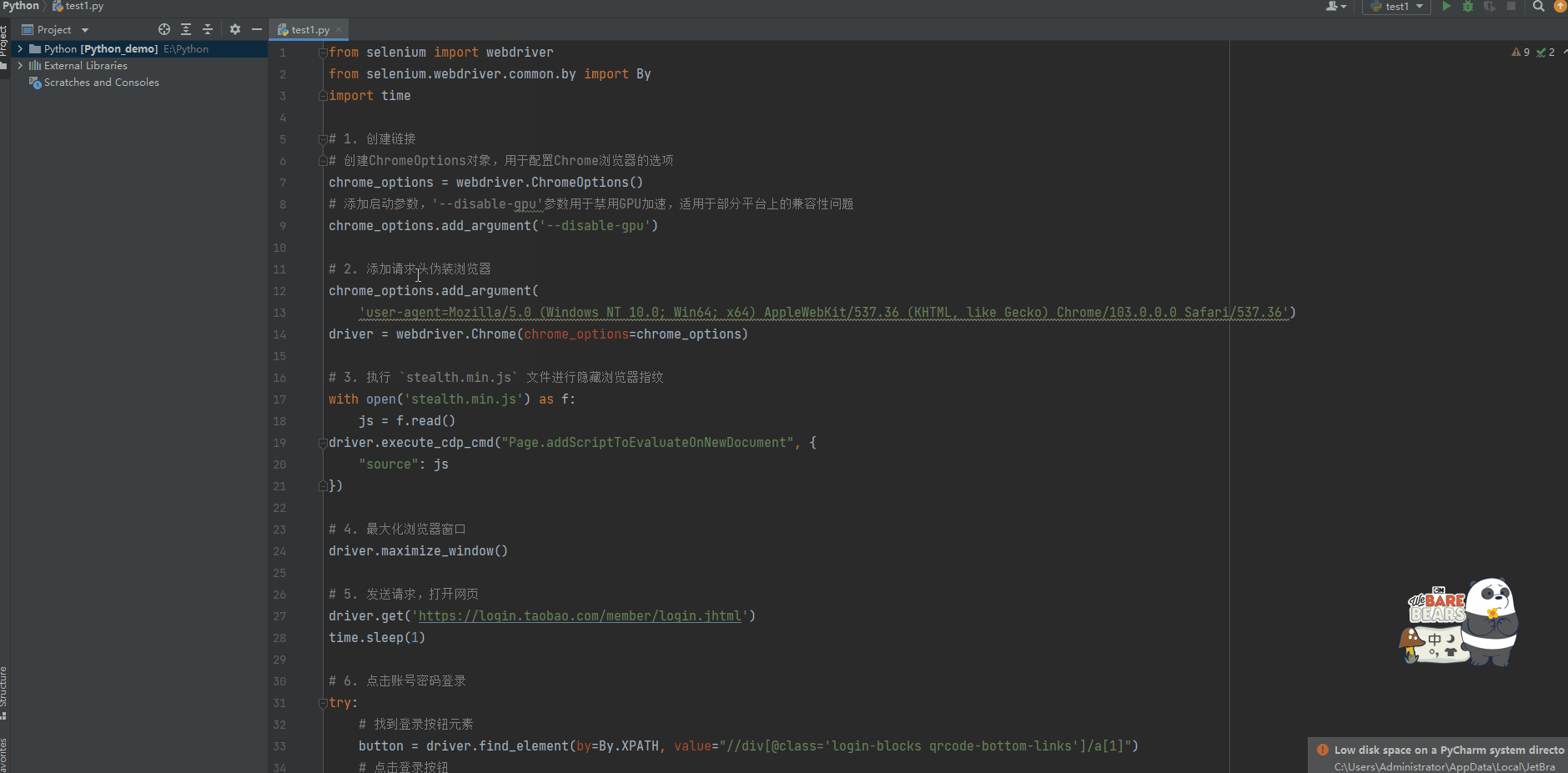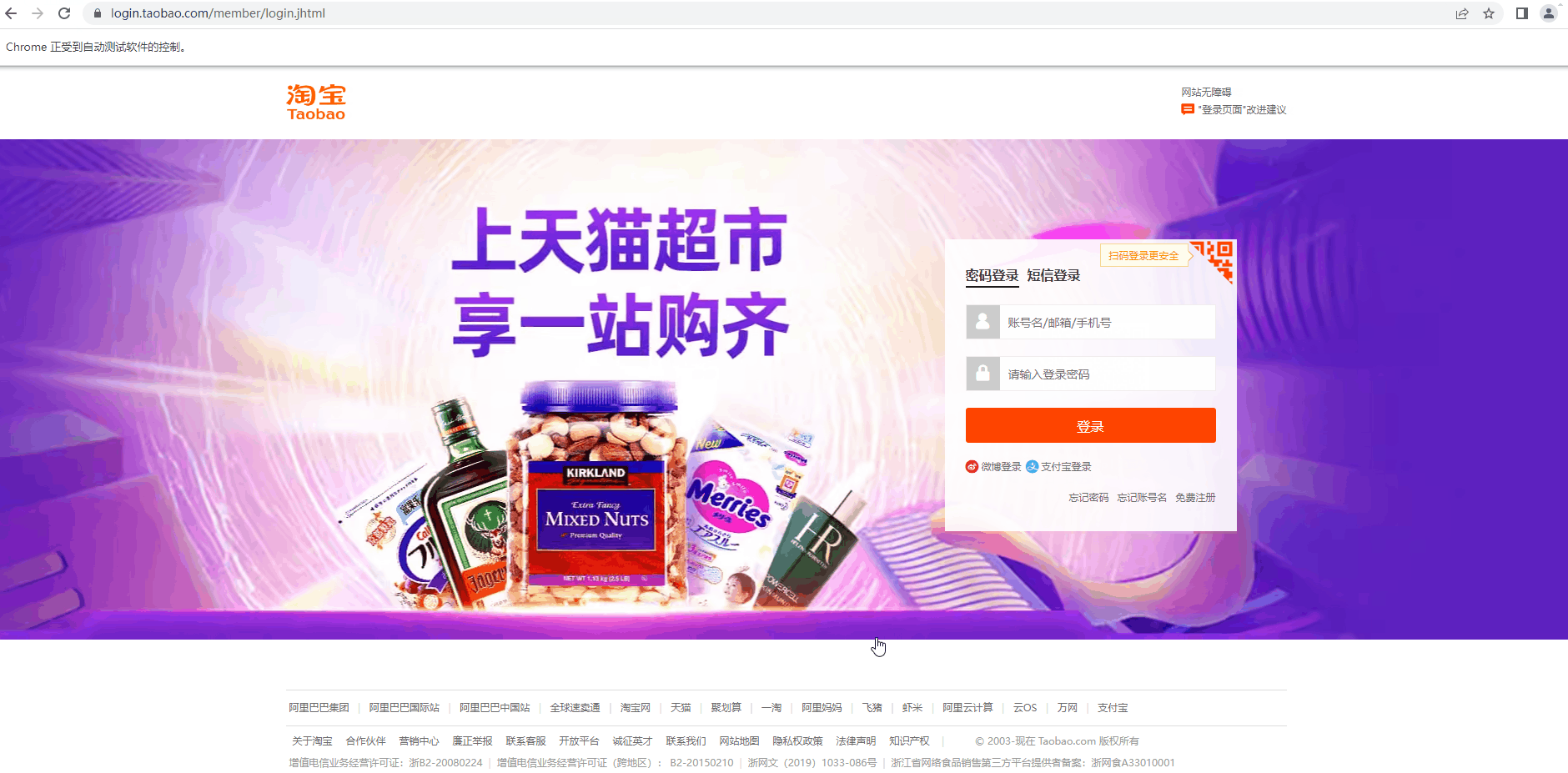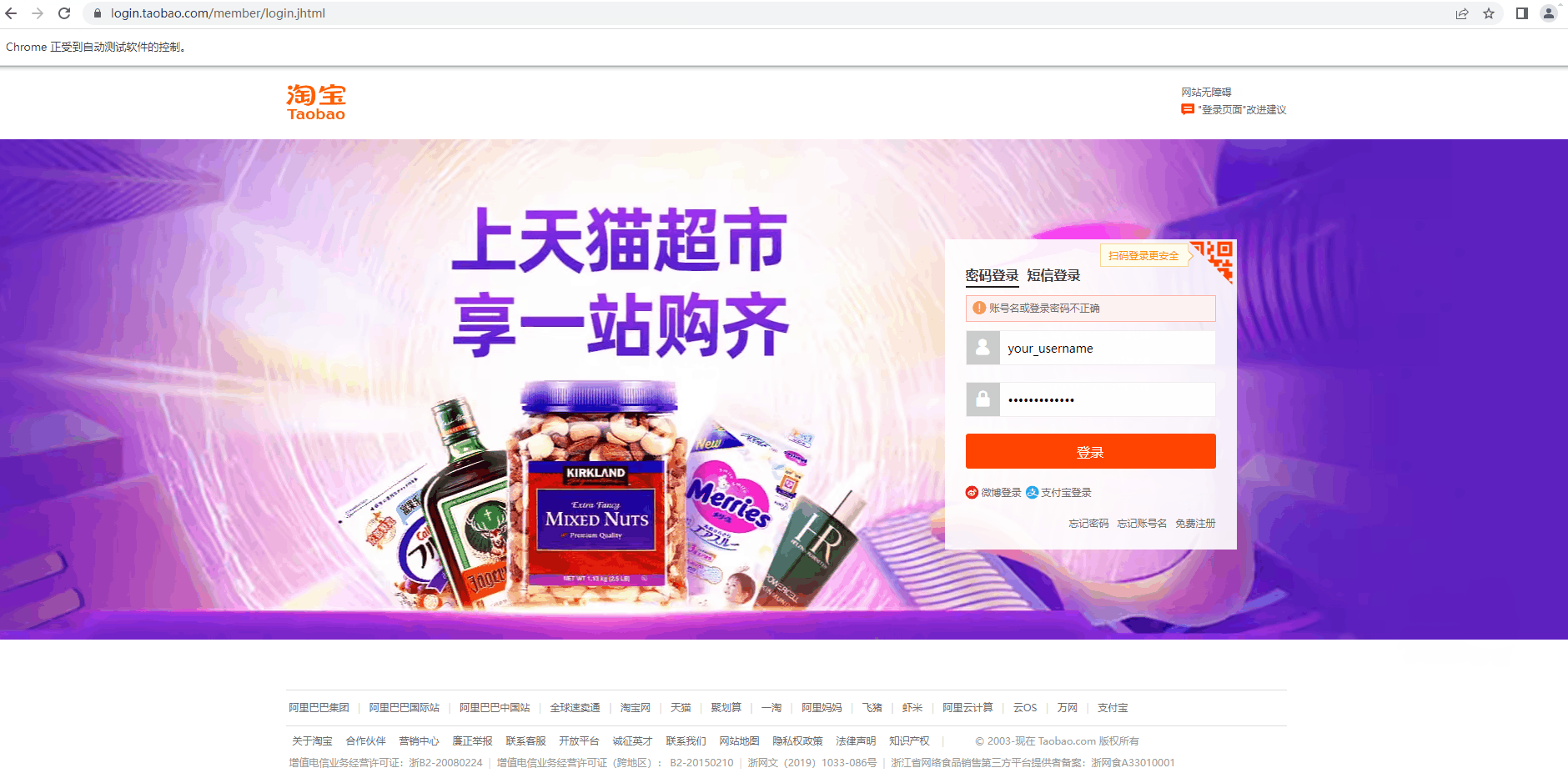
下面是某宝的登录界面,接下来我们需要实现的步骤是:
- 1、打开网页
- 2、输入账号信息
- 3、输入密码信息
- 4、点击 “登录” 按钮
3. 基础补充
由于某宝的反爬技术很高超,这里我们需要用到网页元素定位操作和隐藏浏览器指纹,还不会的小伙伴学习一下专栏文章:
- 100天精通Python(爬虫篇)——第47天:selenium自动化操作浏览器(基础+代码实战)
- 100天精通Python(实用脚本篇)——第115天:基于selenium实现反反爬策略之隐藏浏览器指纹特征
4. 代码实战
4.1 创建连接
from selenium import webdriver from selenium.webdriver.common.by import By import time # 1. 创建连接 # 创建ChromeOptions对象,用于配置Chrome浏览器的选项 chrome_options = webdriver.ChromeOptions() # 添加启动参数,'--disable-gpu'参数用于禁用GPU加速,适用于部分平台上的兼容性问题 chrome_options.add_argument('--disable-gpu')4.2 添加请求头伪装浏览器
通过添加请求头伪装成正常的浏览器信息:
(图片来源网络,侵删)# 2. 添加请求头伪装浏览器 chrome_options.add_argument( 'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36') driver = webdriver.Chrome(chrome_options=chrome_options)4.3 隐藏浏览器指纹
执行 stealth.min.js 文件进行隐藏浏览器指纹特征:
# 3. 执行 `stealth.min.js` 文件进行隐藏浏览器指纹 with open('stealth.min.js') as f: js = f.read() driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": js })4.4 最大化窗口
为了方便大家看登录操作,设置浏览器 全屏:
# 4. 最大化浏览器窗口 driver.maximize_window()
4.5 启动网页
# 5. 发送请求,打开网页 driver.get('https://login.taobao.com/member/login.jhtml') time.sleep(1)4.6 点击密码登录
1、有时候打开某宝的登录界面,它想让我们扫码登录,这时候我们就需要点击密码登录:
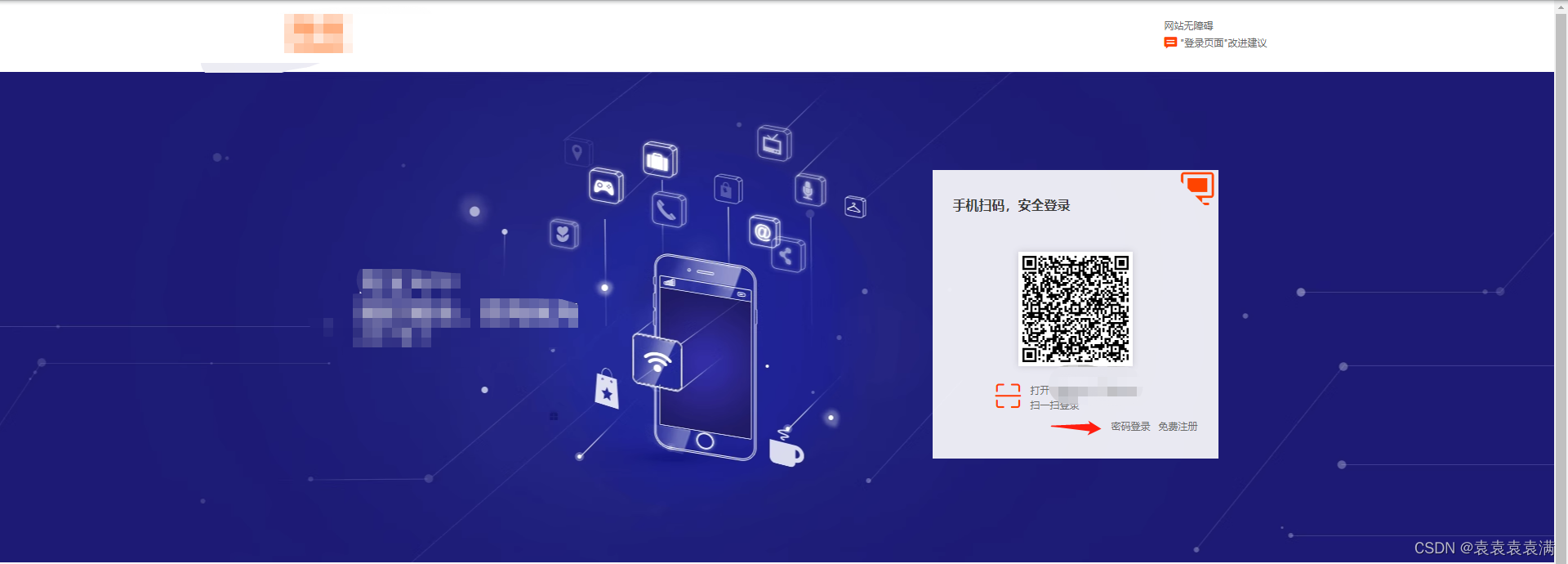
2、这个标签有个js,本想通过执行js点击元素,结果发现执行不成功也不报错(原因未知大家可以自行尝试下),所以选择定位xpath:
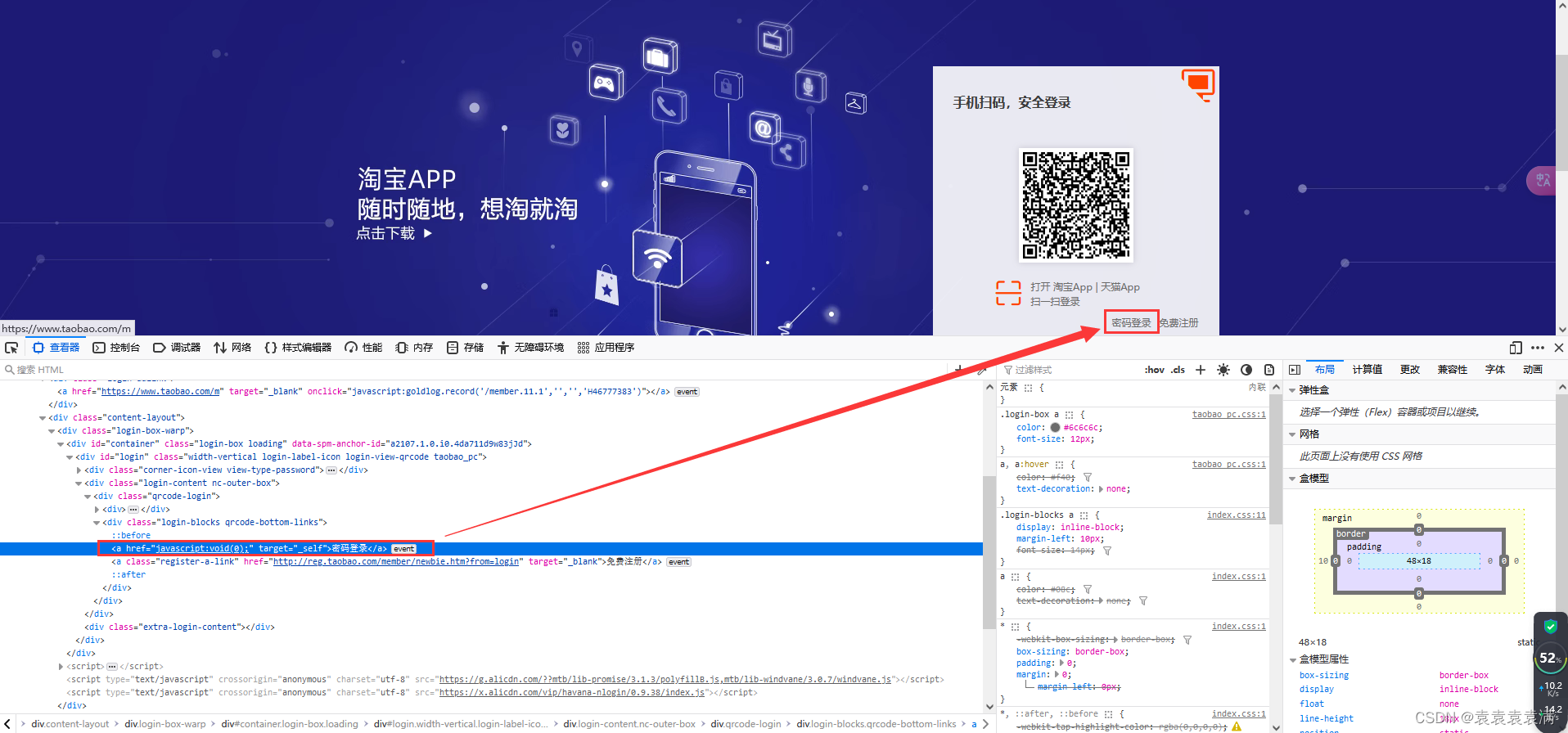 (图片来源网络,侵删)
(图片来源网络,侵删)元素的xpath地址:
//div[@class='login-blocks qrcode-bottom-links']/a[1]
3、通过find_element方法定位元素的xpath,由于这个界面是有几率触发,所以写一个异常捕获防止报错,通过click()方法点击元素:
# 6. 点击账号密码登录 try: # 找到登录按钮元素 button = driver.find_element(by=By.XPATH, value="//div[@class='login-blocks qrcode-bottom-links']/a[1]") # 点击登录按钮 button.click() except: pass4.7 输入账号密码
注意事项:有ID找ID(ID是唯一的),没ID找其他标签
1、确定账号、密码输入框的标签信息:
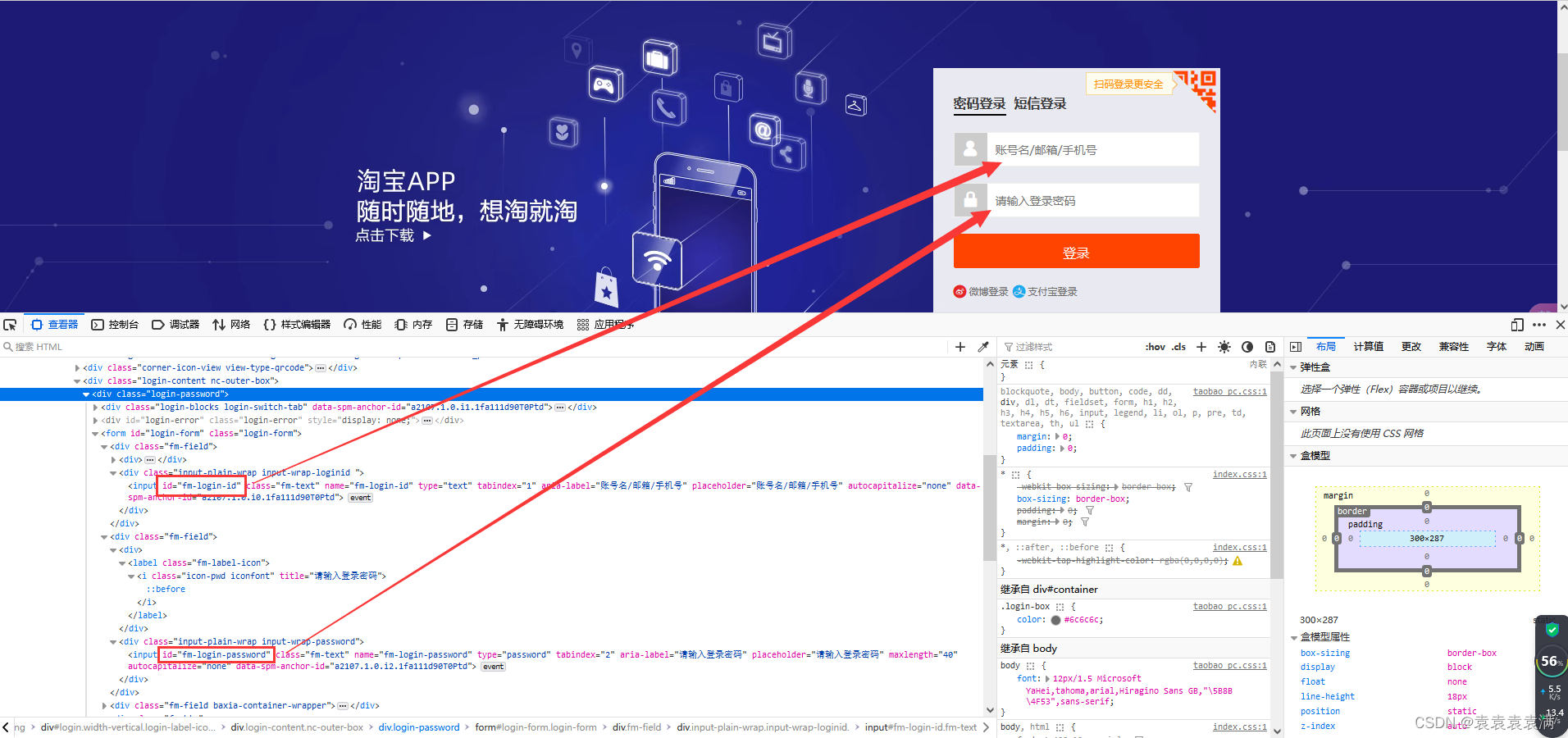
账号框ID为:
fm-login-id
密码框ID为:
fm-login-password
2、通过find_element方法定位文本框,通过send_keys方法输入账号信息:
# 7. 输入账号密码 username_input = driver.find_element(by=By.ID, value="fm-login-id") # 定位账号框 username_input.send_keys("your_username") # 输入账号信息(这里自行替换) password_input = driver.find_element(by=By.ID, value="fm-login-password") # 定位密码框 password_input .send_keys("your_username") # 输入密码信息(这里自行替换)4.8 点击登录按钮
1、刚开始试过,用这个登录按钮classes ID定位,但是代码无法定位成功,所以还是选择xpath定位:
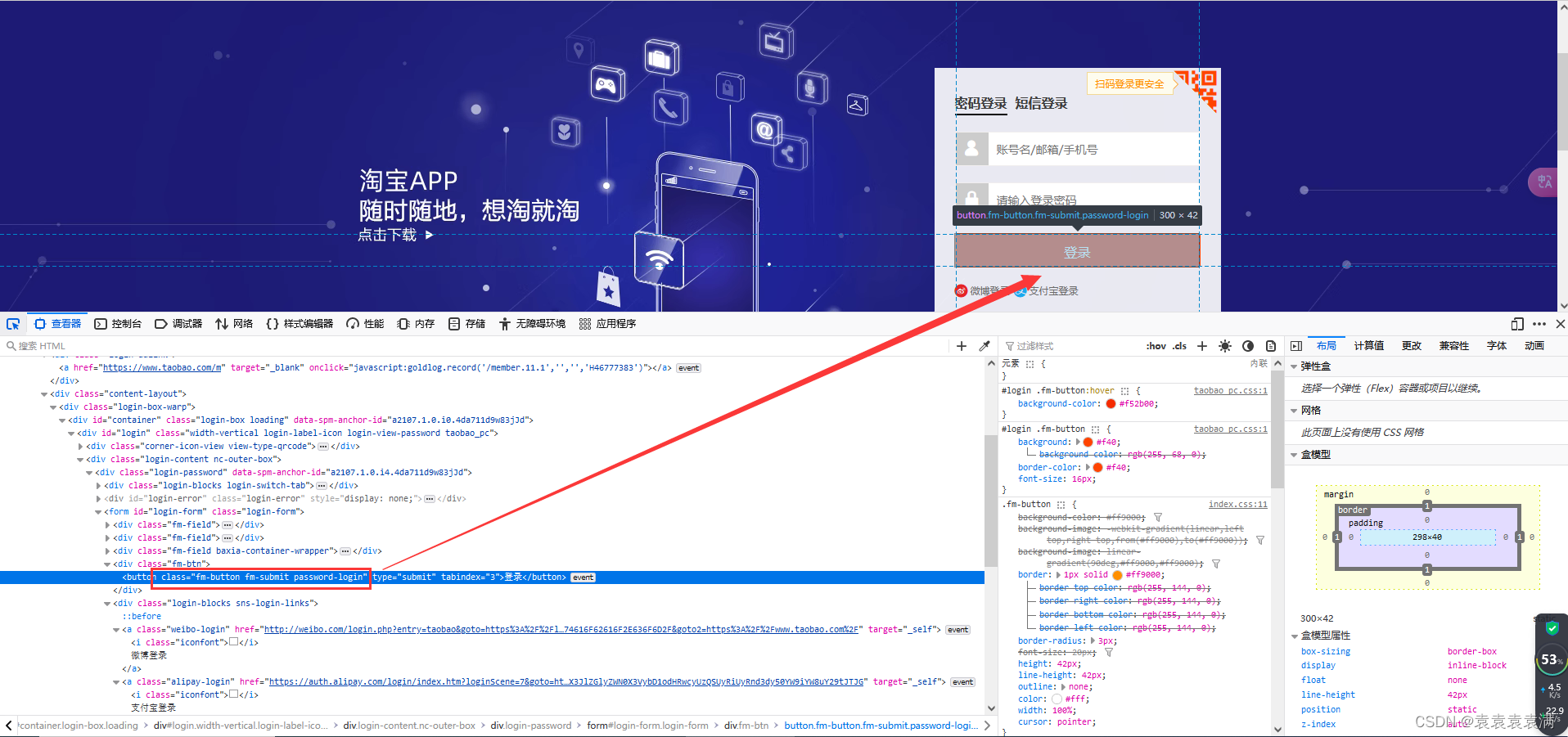
登录按钮xpath地址:
//button[@class='fm-button fm-submit password-login']
2、通过find_element方法定位xpath,通过click()方法点击元素:
# 8. 点击登录按钮元素 login_button = driver.find_element(by=By.XPATH, value="//button[@class='fm-button fm-submit password-login']") # 点击登录按钮 login_button.click()
4.9 完整代码
下面是完整登录代码,需要替换自己的账号密码:
from selenium import webdriver from selenium.webdriver.common.by import By import time # 1. 创建链接 # 创建ChromeOptions对象,用于配置Chrome浏览器的选项 chrome_options = webdriver.ChromeOptions() # 添加启动参数,'--disable-gpu'参数用于禁用GPU加速,适用于部分平台上的兼容性问题 chrome_options.add_argument('--disable-gpu') # 2. 添加请求头伪装浏览器 chrome_options.add_argument( 'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36') driver = webdriver.Chrome(chrome_options=chrome_options) # 3. 执行 `stealth.min.js` 文件进行隐藏浏览器指纹 with open('stealth.min.js') as f: js = f.read() driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": js }) # 4. 最大化浏览器窗口 driver.maximize_window() # 5. 发送请求,打开网页 driver.get('https://login.taobao.com/member/login.jhtml') time.sleep(1) # 6. 点击账号密码登录 try: # 找到登录按钮元素 button = driver.find_element(by=By.XPATH, value="//div[@class='login-blocks qrcode-bottom-links']/a[1]") # 点击登录按钮 button.click() except: pass # 7. 输入账号密码 username_input = driver.find_element(by=By.ID, value="fm-login-id") # 定位账号框 username_input.send_keys("your_username") # 输入账号信息(这里自行替换) password_input = driver.find_element(by=By.ID, value="fm-login-password") # 定位密码框 password_input .send_keys("your_username") # 输入密码信息(这里自行替换) # 8. 点击登录按钮元素 login_button = driver.find_element(by=By.XPATH, value="//button[@class='fm-button fm-submit password-login']") # 点击登录按钮 login_button.click() # 9. 接下来就可以进行网页信息的解析了,自行编写。。。4.10 GIF动图展示
五、总结
爬虫是一个很玄学的技术,本文中4.6执行js和4.8元素定位操作明明是正确的却还是要报错,就不得不换一种网页元素定位方法,所以大家遇到报错不要心慌,不妨换一个操作进行尝试,我们下期见!
——第117天:基于selenium实现反反爬策略之代码输入账号信息登录网站,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,我们,方法,设置,第1张")
——第117天:基于selenium实现反反爬策略之代码输入账号信息登录网站,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,我们,方法,设置,第5张")
——第117天:基于selenium实现反反爬策略之代码输入账号信息登录网站,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,我们,方法,设置,第8张")
")
")
")
还没有评论,来说两句吧...