

自然语言处理(NLP)-spacy简介以及安装指南(语言库zh
- spacy 简介
spacy 是 Python 自然语言处理软件包,可以对自然语言文本做词性分析、命名实体识别、依赖关系刻画,以及词嵌入向量的计算和可视化等。
(图片来源网络,侵删)1.安装 spacy
使用 “pip install spacy" 报错, 或者安装完 spacy,无法正常调用,可以通过以下链接将 whl 文件下载到本地,然后 cd 到文件路径下,通过 pip 安装。
pip install spacy
下载链接:
Archived: Python Extension Packages for Windows - Christoph Gohlke (uci.edu)
选择对应的版本:

2. 语言库安装
2.1 zh_core_web_sm
2.1:英文 = python -m spacy download en_core_web_sm 2.2:中文 = python -m spacy download zh_core_web_sm
可以手动下载包再安装 下载地址 = https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.7.0/zh_core_web_sm-3.7.0-py3-none-any.whl 下载好之后执行命令:pip install zh_core_web_sm-3.7.0-py3-none-any.whl
通过下方链接下载 whl 文件到本地:
(图片来源网络,侵删)zh_core_web_sm · Releases · explosion/spacy-models (github.com)
选择对应的版本:
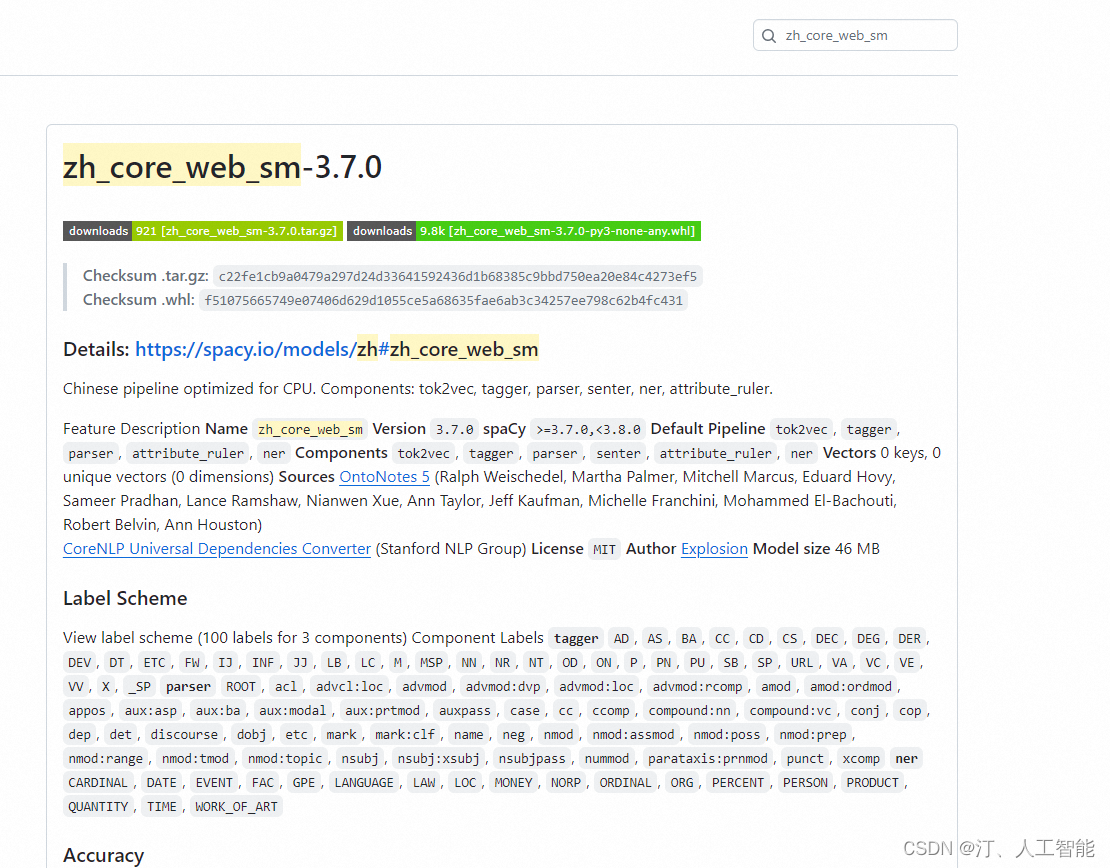
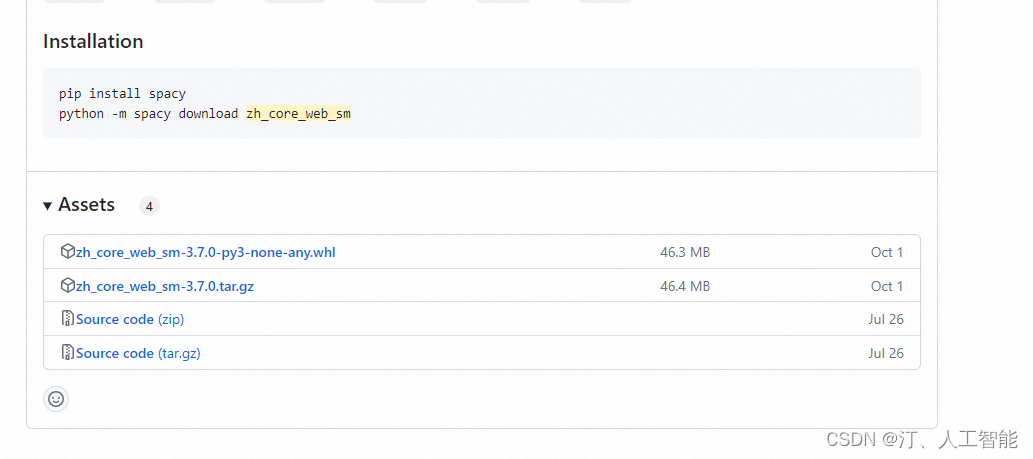
下载好对应版本的 zh_core_web_sm.whl 文件,cd 文件保存目录,然后通过 pip 安装。
pip install spacy python -m spacy download zh_core_web_sm
安装成功提示:
(图片来源网络,侵删)
2.2 安装 en_core_web_sm
通过下方链接下载 whl 文件到本地:
en_core_web_sm · Releases · explosion/spacy-models (github.com)
选择对应的版本:
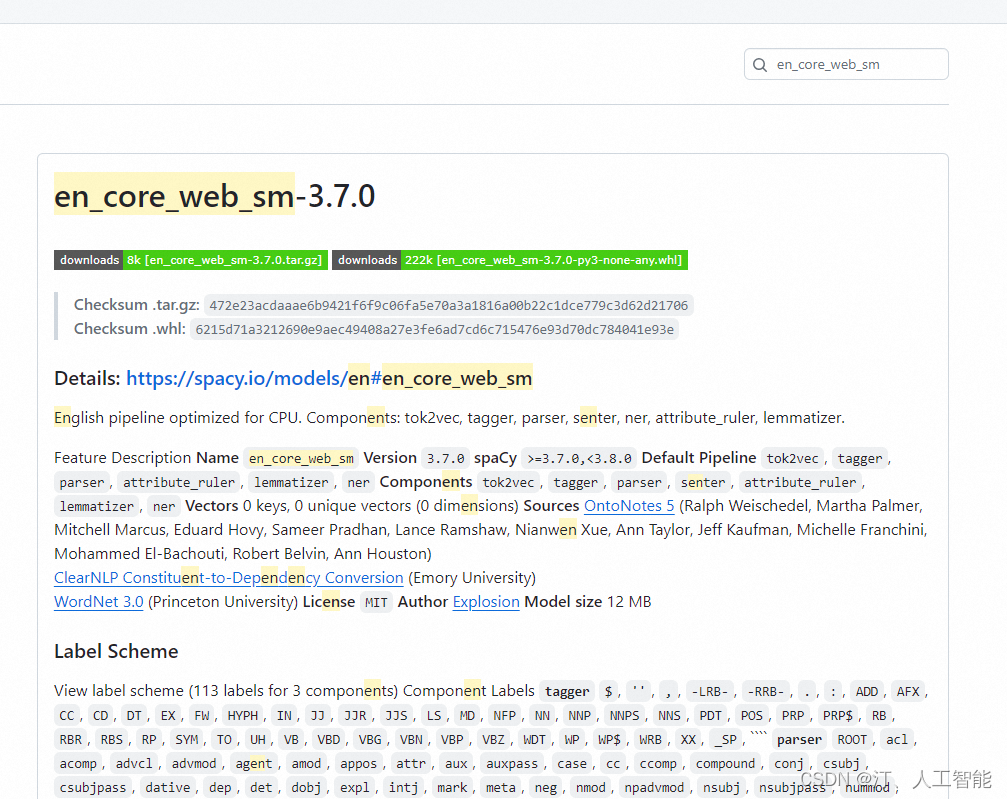
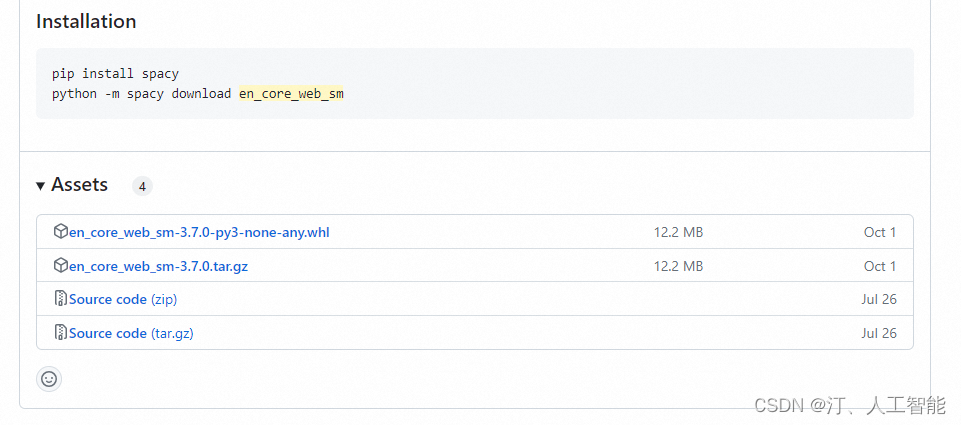
下载好对应版本的 zh_core_web_sm.whl 文件,cd 文件保存目录,然后通过 pip 安装。
3.效果测试
3.1 英文测试
# 导入英文类 from spacy.lang.en import English # 实例化一个nlp类对象,包含管道pipeline nlp = English() # print(nlp) doc = nlp("December is excited!") # 迭代tokens for token in doc: print(token.text) token = doc[1] print(token.text)输出结果:
December is excited ! is
3.2 中文测试
# 处理文本 nlp = spacy.load('zh_core_web_sm') doc = nlp("英伟达准备用20亿美金买下这家法国的创业公司。") # 遍历识别出的实体 for ent in doc.ents: # 打印实体文本及其标注 print(ent.text, ent.label_)输出结果:
英伟达 ORG 20亿美金 MONEY 法国 NORP
-spacy简介以及安装指南(语言库zh,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,使用,自然语言处理,安装,第1张")
-spacy简介以及安装指南(语言库zh,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,使用,自然语言处理,安装,第3张")
-spacy简介以及安装指南(语言库zh,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,使用,自然语言处理,安装,第6张")
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。
")

")
")
还没有评论,来说两句吧...