

爬取某牙视频
爬取页面链接:游戏视频_游戏攻略_虎牙视频

(图片来源网络,侵删)
爬取步骤:点进去一个视频播放,查看media看有没有视频,发现没有。在xhr中发现有许多ts文件,但这种不是很长的视频一般都有直接的播放链接,所以目标还是找直接的链接。在搜索中搜索ts文件的某一个参数,或直接搜m3u8可以找到getmonment的包,里面有下载的链接。而这个包的链接与视频id有关
一页如何下载:在主界面找到含有多个视频id的包,爬取视频id和视频名称,再循环将id赋值给getmonment的包的链接,实现一页下载。
多页下载:观察主界面的包找url的规律即可。
代码展现:
import requests
import re
import os
from tqdm import tqdm
filename = 'video虎牙\'
if not os.path.exists(filename):
os.mkdir(filename)
url = 'https://www.huya.com/video/g/all?set_id=37&order=hot&page=1'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
response = requests.get(url=url,headers=headers).text
id_list = re.findall('\{"vid":(.*?),',response)
for id in tqdm(id_list):
headers1 = {
"Referer":"https://www.huya.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
link = f'https://liveapi.huya.com/moment/getMomentContent?videoId={id}&uid=&_=1708997648767'
json_data = requests.get(url=link,headers=headers).json()
video_name = json_data['data']['moment']['title']
video_url = json_data['data']['moment']['videoInfo']['definitions'][0]['url']
print(f'正在下载:{video_name}')
video_content = requests.get(url=video_url,headers=headers1).content
with open(filename+video_name+'.mp4','wb') as f:
f.write(video_content)
结果展现: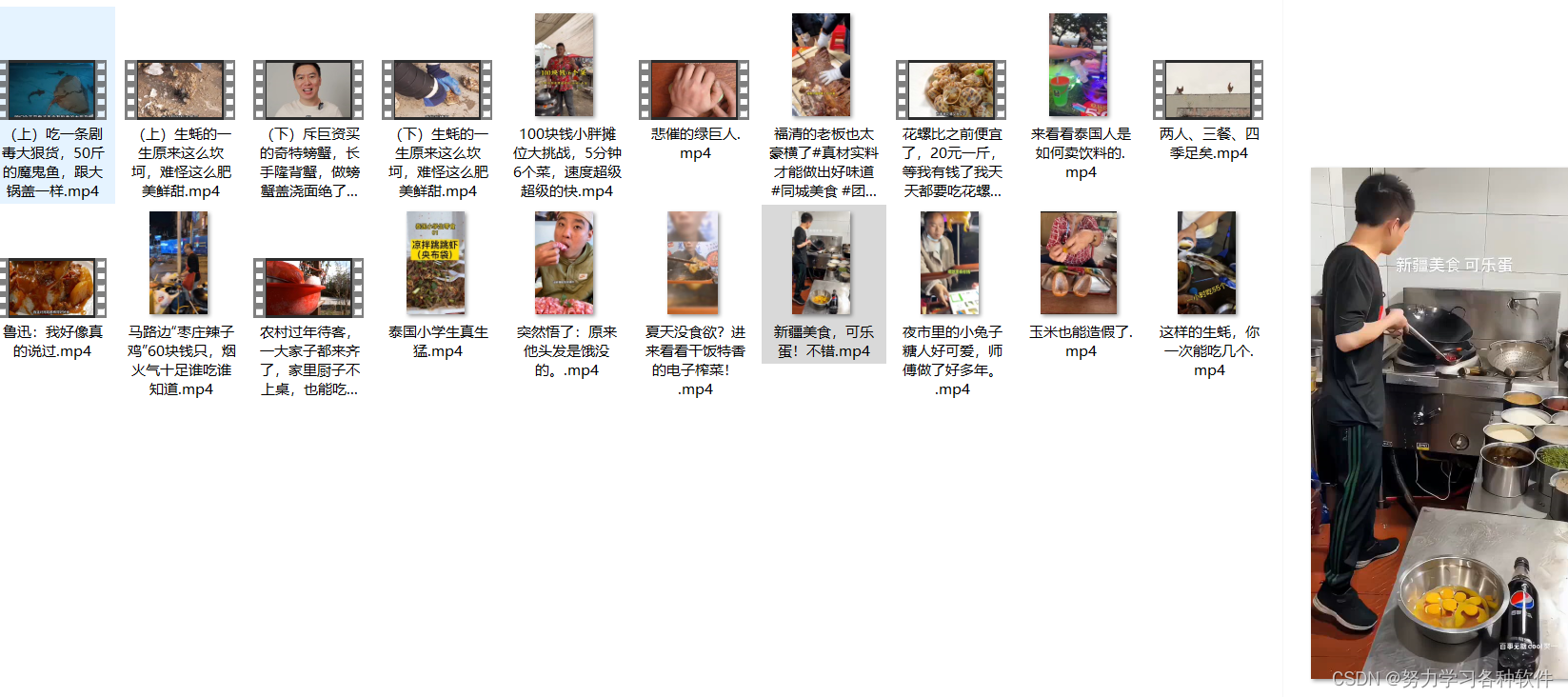

(图片来源网络,侵删)

(图片来源网络,侵删)
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。
")
")
")

还没有评论,来说两句吧...