

深入理解分库、分表、分库分表
前言
分库分表,是企业里面比较常见的针对高并发、数据量大的场景下的一种技术优化方案,所谓"分库分表",根本就不是一件事儿,而是三件事儿,他们要解决的问题也都不一样,这三个事儿分别是"只分库不分表"、"只分表不分库”、以及"既分库又分表"。本文我们一起理解分库、分表的奥秘。

分库主要解决的是并发量大的问题。因为并发量一旦上来了,那么数据库就可能会成为瓶颈,因为数据库的连接数是有限的,虽然可以调整,但是也不是无限调整的。所以,当你的数据库的读或者写的QPS过高,导致你的数据库连接数不足了的时候,就需要考虑分库了,通过增加数据库实例的方式来提供更多的可用数据库链接,从而提升系统的并发度。
分表主要解决的是数据量大的问题。假如你的单表数据量非常大,因为并发不高,数据量连接可能还够,但是存储和查询的性能遇到了瓶颈了,你做了很多优化之后还是无法提升效率的时候,就需要考虑做分表了。
那么,当你的数据库链接也不够了,并且单表数据量也很大导致査询比较慢的时候,就需要做既分库又分表了
分库、分表、分库分表
分库主要解决的是并发量大的问题。比较典型的分库的场景就是我们在做微服务拆分的时候,就会按照业务边界把各个业务的数据从一个单一的数据库中拆分开,分别把订单、物流、商品、会员等数据,分别放到单独的数据库中。
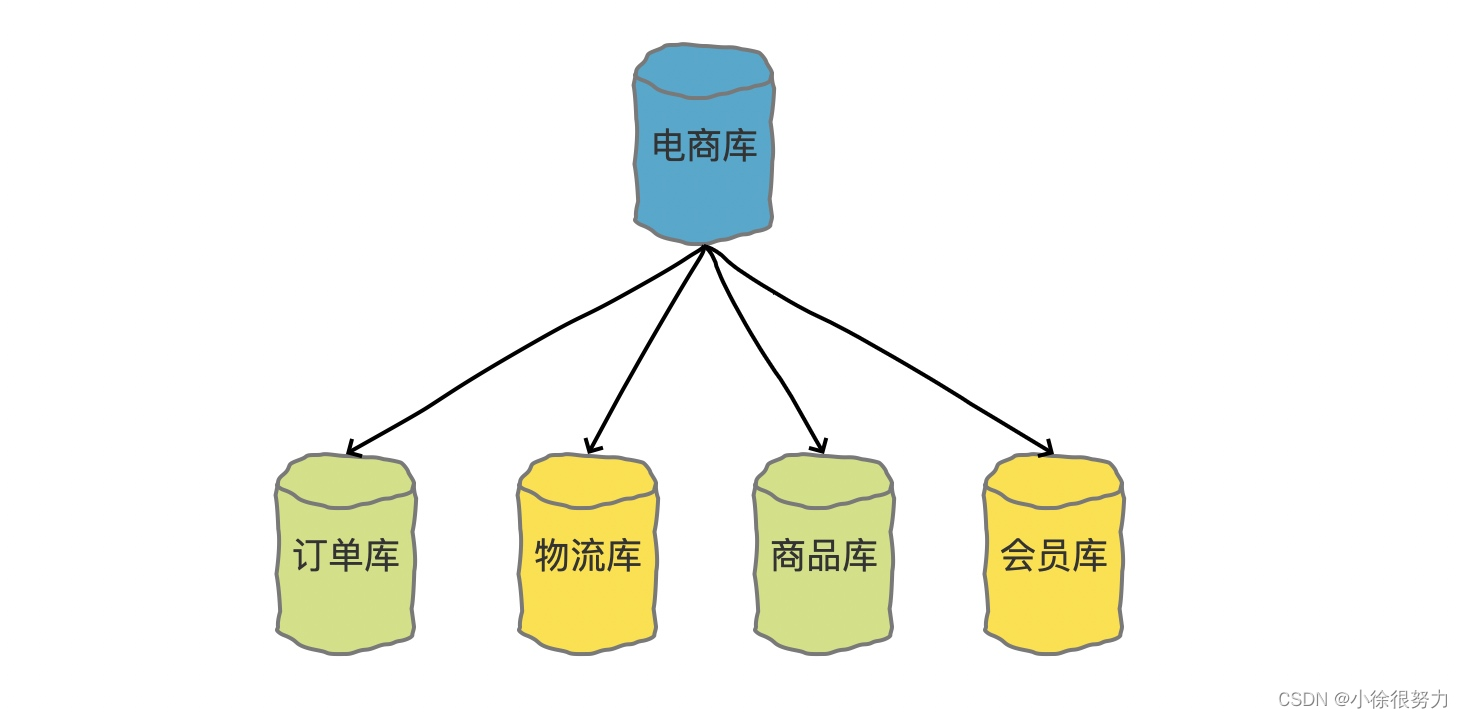 还有就是有的时候可能会需要把历史订单挪到历史库里面去。这也是分库的一种具体做法
还有就是有的时候可能会需要把历史订单挪到历史库里面去。这也是分库的一种具体做法
什么时候分表?
分表主要解决的是数据量大的问题。通过将数据拆分到多张表中,来减少单表的数据量,从而提升查询速度


一般我们认为,单表行数超过 500 万行或者单表容量超过 2GB之后,才需要考虑做分库分表了,小于这个数据量,遇到性能问题先建议大家通过其他优化来解决,
PS:以上数据,是阿里巴巴Java开发手册中给出的数据,偏保守,根据实际经验来说,单表抗2000万数据量问题不大,但具体的数据里还是要看记录大小、存储引擎设置、硬件配置等。
那如果,既需要解决并发量大的问题,又需要解决数据量大的问题时候。通常情况下,高并发和数据量大的问题都是同时发生的,所以,我们会经常遇到分库分表需要同时进行的情况。
所以,当你的数据库链接也不够了,并且单表数据量也很大导致査询比较慢的时候,就需要做既分库又分表了
横向拆分和纵向拆分
谈及到分库分表,那就要涉及到该如何做拆分的问题。

通常在做拆分的时候有两种分法,分别是横向拆分(水平拆分)和纵向拆分(垂直拆分)。假如我们有一张表,如果把这张表中某一条记录的多个字段,拆分到多张表中,这种就是纵向拆分。那如果把一张表中的不同的记录分别放到不同的表中,这种就是横向拆分。
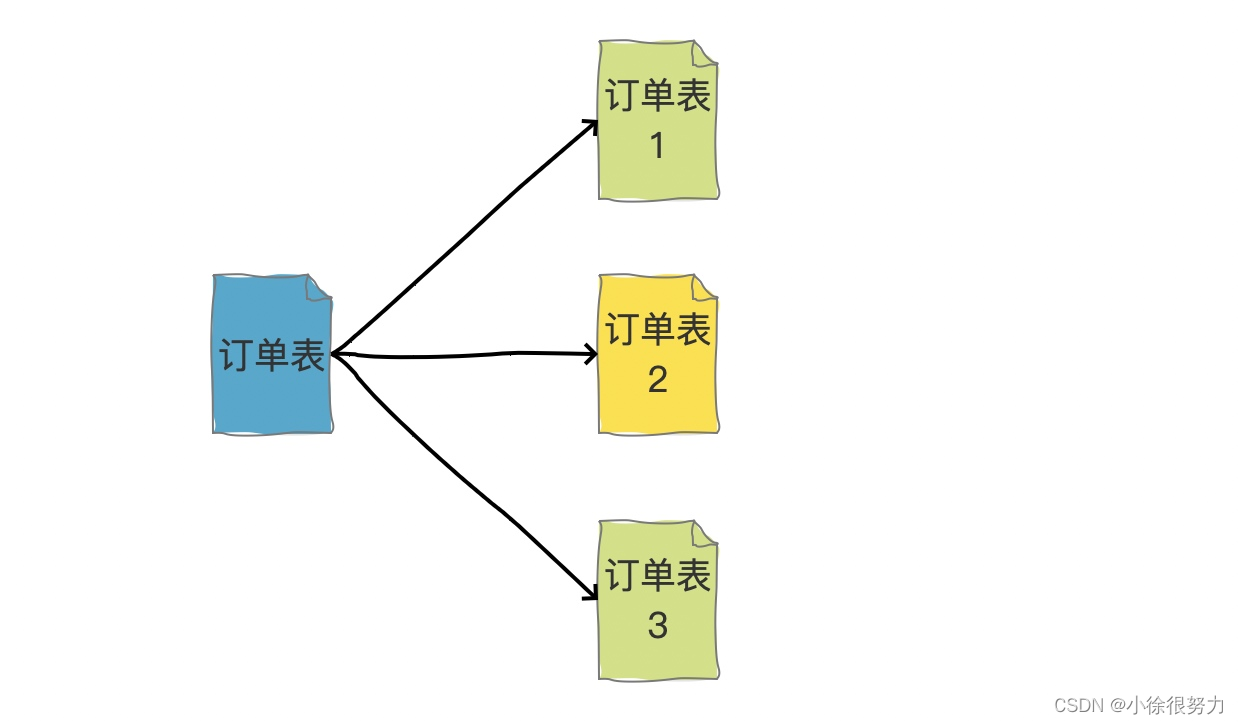
横向拆分的结果是数据库表中的数据会分散到多张分表中,使得每一个单表中的数据的条数都有所下降。比如我们可以把不同的用户的订单分表拆分放到不同的表中。
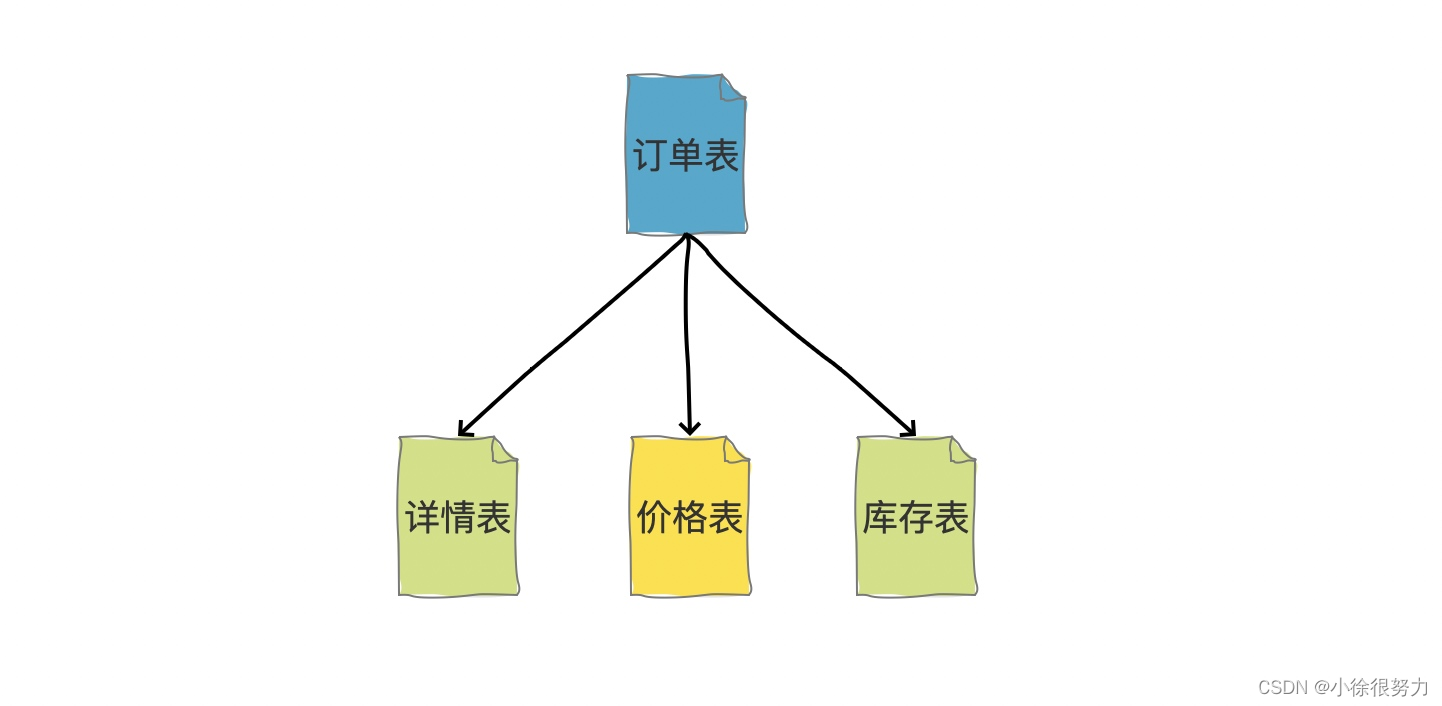
 纵向拆分的结果是数据库表中的数据的字段数会变少,使得每一个单表中的数据的存储有所下降。比如我可以把商品详情信息、价格信息、库存信息等等分别拆分到不同的表中,
纵向拆分的结果是数据库表中的数据的字段数会变少,使得每一个单表中的数据的存储有所下降。比如我可以把商品详情信息、价格信息、库存信息等等分别拆分到不同的表中,
分表字段如何选择?
在分库分表的过程中,我们需要有一个字段用来进行分表,比如按照用户分表、按照时间分表、按照地区分表。这里面的用户、时间、地区就是所谓的分表字段。
那么,在选择这个分表字段的时候,一定要注意,要根据实际的业务情况来做慎重的选择。
比如说我们要对交易订单进行分表的时候,我们可以选择的信息有很多,比如买家|d、卖家|d、订单号、时间、地区等等,具体应该如何选择呢?
通常,如果有特殊的诉求,比如按照月度汇总、地区汇总等以外,我们通常建议大家按照买家ld进行分表。因为这样可以避免一个关键的问题那就是--数据倾斜(热点数据)
1、买家还是卖家
首先,我们先说为什么不按照卖家分表?
因为我们知道,电商网站上面是有很多买家和卖家的,但是,一个大的卖家可能会产生很多订单,比如像苏宁易购、当当等这种店铺,他每天在天猫产生的订单量就非常的大。如果按照卖家!d分表的话,那同一个卖家的很多订单都会分到同一张表。
那就会使得有一些表的数据量非常的大,但是有些表的数据量又很小,这就是发生了数据倾斜。这个卖家的数据就变成了热点数据,随着时间的增长,就会使得这个卖家的所有操作都变得异常缓慢。
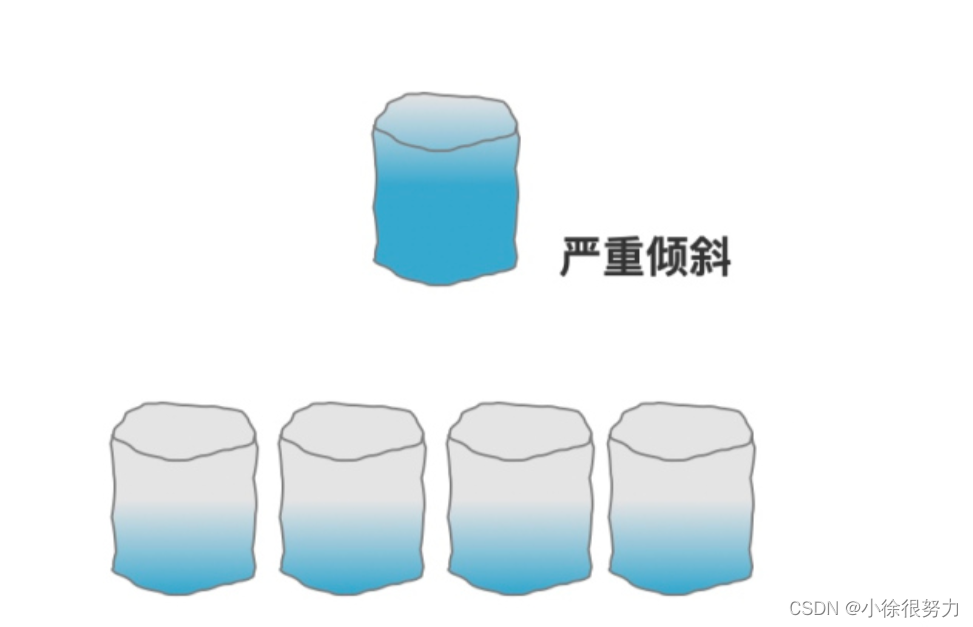 但是,买家ID做分表字段就不会出现这类问题,因为不太容易出现一个买家能把数据买倾斜了。
但是,买家ID做分表字段就不会出现这类问题,因为不太容易出现一个买家能把数据买倾斜了。
但是需要注意的是,我们说按照买家Id做分表,保证的是同一个买家的所有订单都在同一张表,并不是要给每个买家都单独分配一张表。
我们在做分表路由的时候,是可以设定一定的规则的,比如我们想要分1024张表,那么我们可以用买家ID或者买家ID的hashcode对1024取模,结果是0000-1023,那么就存储到对应的编号的分表中就行了。
2、卖家查询怎么办
如果按照买家Id进行了分表,那卖家的查询怎么办,这不就意味着要跨表查询了吗?
首先,业务问题我们要建立在业务背景下讨论。电商网站订单查询有几种场景?
- 买家查自己的订单
- 卖家查自己的订单
- 平台的小二查用户的订单。
首先,我们用买家ID做了分表,那么买家来查询的时候,是一定可以把买家!D带过来的,我们直接去对应的表里面查询就行了。
那如果是卖家查呢?卖家查询的话,同样可以带卖家id过来,那么,我们可以有一个基于binlog、fink等准实时的同步一张卖家维度的分表,这张表只用来查询,来解决卖家查询的问题。
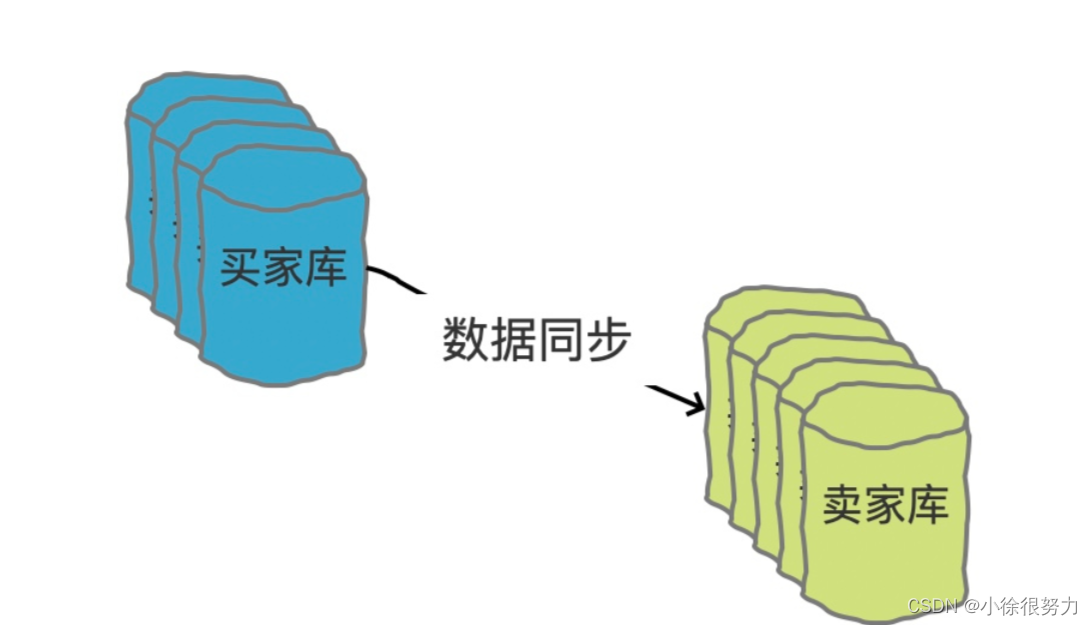
本质上就是用空间换时间的做法。
不知道大家看到这里会不会有这样的疑问:同步一张卖家表,这不又带来了大卖家的热点问题了吗?
首先,我们说同步一张卖家维度的表来,但是其实所有的写操作还是要写到买家表的,只不过需要准实时同步的方案同步到卖家表中。也就是说,我们的这个卖家表理论上是没有业务的写操作,只有读操作的。
所以,这个卖家库只需要有高性能的读就行了,那这样的话就可以有很多选择了,比如可以部署到一些配置不用那么高的机器、或者其实可以干脆就不用MYSQL,而是采用HBASE、PolarDB、Lindorm等数据库就可以了。这些数据库都是可以海量数据,并提供高性能查询的。
还有呢就是,大卖家一般都是可以识别的,提前针对大卖家,把他的订单,再按照一定的规则拆分到多张表中。因为只有读,没有写操作,所以拆分多张表也不用考虑事务的问题。
这里说的没有写指的是不会主动操作这张卖家表做更新,他的数据都是从买家表同步过来的,这个同步的事务在买家表已经处理过了,卖家表只需要负责同步。
卖家更新数据也一样,都是基于订单号更新的,订单号上面是带来分表信息的,直接到买家表去更新,然后同步到卖家表。
3、订单查询怎么办
上面说的都是有买卖家ID的情况,那没有买卖家ID呢?用订单号直接查怎么办呢?
这种问题的解决方案是,在生成订单号的时候,我们一般会把分表结果编码到订单号中去,因为订单生成的时候是一定可以知道买家ID的,那么我们就把买家ID的路由结果比如1023,作为一段固定的值放到订单号中就行了。这就是所谓的“基因法”
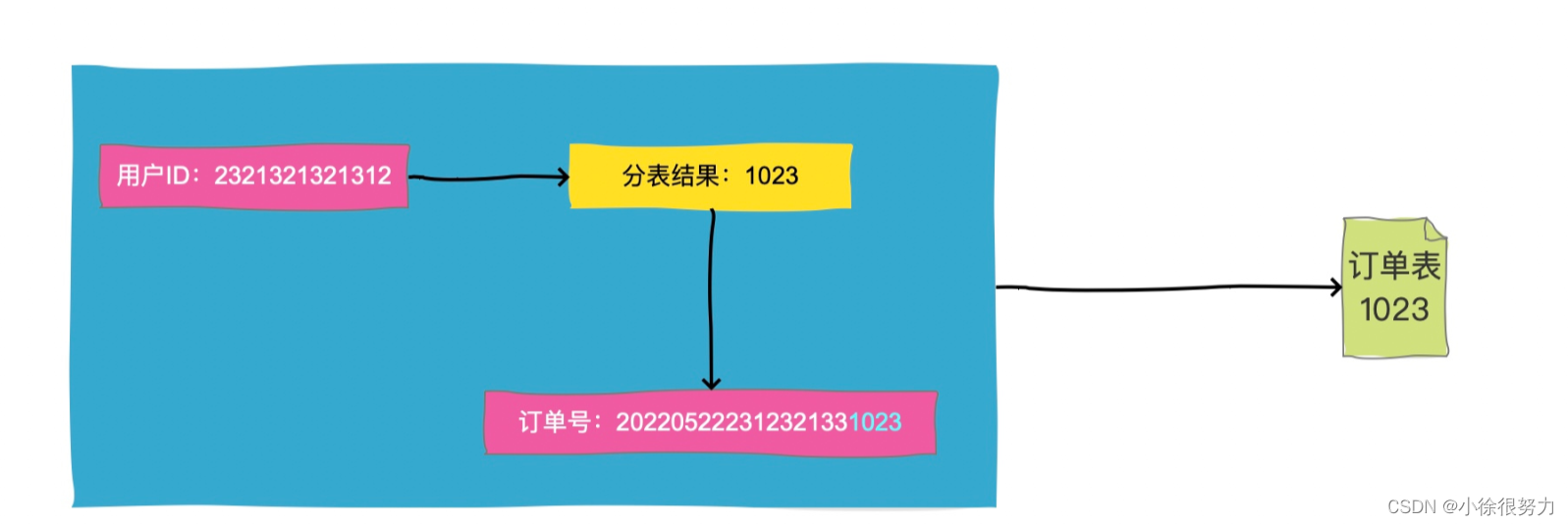 这样按照订单号查询的时候,解析出这段数字,直接去对应分表查询就好了。
这样按照订单号查询的时候,解析出这段数字,直接去对应分表查询就好了。
至于还有人问其他的查询,没有买卖家ID,也没订单号的,那其实就属于是低频查询或者非核心功能査询了,那就可以用ES等搜索引擎的方案来解决了。就不述了。
总结
本篇我们对分库分表有了初步的了解,接下来我们具体讨论分库分表的一些常用方法。
")
")
")
还没有评论,来说两句吧...