

KMP字符串(算法)
一、KMP算法相关概念:
KMP算法是一个字符串匹配算法,举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?
,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,比较,最后,操作,第1张")
此算法对于暴力算法进行了优化(下面会讲解优化思路),使时间复杂度降为O(n)。
基本概念:
1、s[ ]是模板串,即比较长的字符串。
2、p[ ]是模式串,即比较短的字符串。(暂且这样认为)
3、前缀:指除了最后一个字符以外,一个字符串的全部头部组合。
4、后缀:指除了第一个字符以外,一个字符串的全部尾部组合。(后面会有例子)
5、“部分匹配值”:前缀和后缀的最长共有元素的长度。
6、next[ ]是“部分匹配值表”,即next数组,它存储的是每一个下标对应的“部分匹配值”,是KMP算法的核心。(后面作详细讲解)。
KMP算法优化思路(核心思想):在每次失配时,不是把P串往后移一位,而是把P串往后移动至下一次可以和前面部分匹配的位置,这样就可以跳过大多数的失配步骤。而每次P串移动的步数就是通过查找next[ ]数组确定的。
二、next数组的含义及手动模拟(具体求法和代码在后面)
然后来说明一下next数组的含义:对next[ j ] ,是p[ 1, j ]串中前缀和后缀相同的最大长度(部分匹配值),即 p[ 1, next[ j ] ] = p[ j - next[ j ] + 1, j ]。
比如:
,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,比较,最后,操作,第2张")
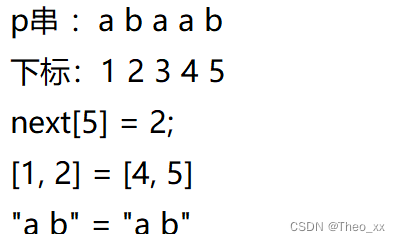
手动模拟求next数组:
对 P = “abcab”
| P | a | b | c | a | b |
| 下标 | 1 | 2 | 3 | 4 | 5 |
| next[ ] | 0 | 0 | 0 | 1 | 2 |
对next[ 1 ] :前缀 = 空集—————后缀 = 空集—————next[ 1 ] = 0;
对next[ 2 ] :前缀 = { a }—————后缀 = { b }—————next[ 2 ] = 0;
,词库加载错误:未能找到文件“C:\Users\Administrator\Desktop\火车头9.8破解版\Configuration\Dict_Stopwords.txt”。,比较,最后,操作,第4张")
对next[ 3 ] :前缀 = { a , ab }—————后缀 = { c , bc}—————next[ 3 ] = 0;
对next[ 4 ] :前缀 = { a , ab , abc }—————后缀 = { a , ca , bca }—————next[ 4 ] = 1;
对next[ 5 ] :前缀 = { a , ab , abc , abca }————后缀 = { b , ab , cab , bcab}————next[ 5 ] = 2;
三、匹配思路和实现代码
KMP主要分两步:求next数组、匹配字符串。个人觉得匹配操作容易懂一些,所以先把匹配字符串讲一下。
s串 和 p串都是从1开始的。i 从1开始,j 从0开始,每次s[ i ] 和p[ j + 1 ]比较。
刚开始可能s[i]和P[j + 1](因为j的初始值为0,但是要注意字符串P和S排序都是从1开始的)一直不一样,那么j保持为0,i递增,直到s[i]第一次等于P[j + 1]。

当匹配过程到上图所示时,
s[ a , b ] = p[ 1, j ] && s[ i ] != p[ j + 1 ] 此时要移动p串(不是移动1格,而是直接移动到下次能匹配的位置)
其中1串为[ 1, next[ j ] ],3串为[ j - next[ j ] + 1 , j ]。由匹配可知 1串等于3串,3串等于2串。所以直接移动p串使1到3的位置即可。这个操作可由j = next[ j ]直接完成。 如此往复下去,当 j == m时匹配成功。
代码如下:
// s[]是长文本,p[]是模式串,n是s的长度,m是p的长度
求模式串的Next数组:
for(int i = 1, j = 0; i > s+1 >> m >> p+1; //下标从1开始
//求next[]数组
for(int i = 2, j = 0; i ")
")
")

还没有评论,来说两句吧...