

基于强化学习的智能机器人路径规划算法研究(附代码)
目录
一.摘要
二.路径规划技术的研究进展
1.研究现状
2.算法分类
2.1 全局路径规划算法
2.2 局部路径规划算法
三.本文采用的路径规划算法——强化学习
1. 概念
2. 与其他机器学习方式的区别
3. 强化学习模型
4.马尔可夫决策过程
5. Q-learning算法
四.算法设计及代码实现
1.UI设计
2.机器人路径规划算法设计
2.1 机器人行进方式
2.2 变量设置:
2.3 算法步骤
五. 算法训练结果分析
1.训练参数
2.训练结果
六.实践过程、体会与反思
七.算法改进和研究展望
1.基于Q-learning算法改进研究现状
2.本文算法的后期改进展望
一.摘要
移动机器人路径规划一直是热门的研究领域,相关的算法丰富多样。本实践前期对机器人路径规划算法做了详细调研,检索并阅读了相关文献,了解了可视图法、人工势场法、启发式算法、神经网络算法等算法在机器人路径规划中的具体应用,本文采用强化学习中的 Q-learning 算法规划机器人的运动路径,做了算 法概念学习、算法代码设计、算法参数调优、算法训练测试等具体工作,查阅相 关开发资料后,决定应用 QT Creator 5.0.2 作为开发环境,采用栅格建模作为算 法应用情景、开发语言为 C++语言。
在完成上述算法设计和算法应用情景开发后,对算法进行仿真验证,训练次 数分别为 200、1000、5000 次,障碍物比例分别设置为 0.2、0.3、0.5,仿真后导 出数据绘制出普通折线图和堆积折线图,呈现结果,也发现了算法收敛速度慢、 初始次数搜索效率低等特点。 最后对本次实践做出总结和反思,对算法改进的方向做了描述,检索并阅读 了大量有关改进强化学习算法规划机器人运动路径的文献,对这些文献一一做了 简要概括。并且对本文算法的未来改进计划做出了初步设想。
关键词:移动机器人 路径规划 强化学习 Q-learning
二.路径规划技术的研究进展
1.研究现状
路径规划是指在规定区域内规划出一条从起始点到目标点的最优解路径,且 要保证与障碍物无碰撞。机器人路径规划存在的难点问题主要有环境建模问题、 算法收敛速度慢以及容易陷入局部最优解问题。[1]
2.算法分类
路径规划可以分为传统算法路径规划和智能仿生算法路径规划两类,其中传统路径规划算法又可以分为全局路径规划算法和局部路径规划算法。
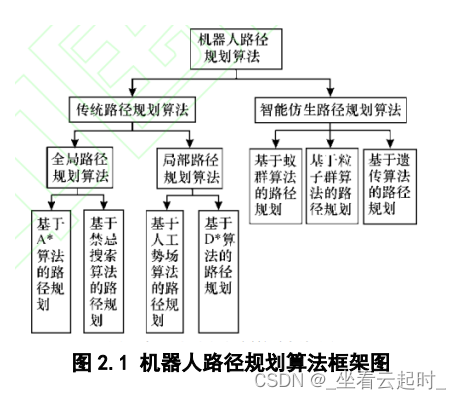
2.1 全局路径规划算法
全局路径规划算法主要包括可视图法、栅格法和自由空间法。
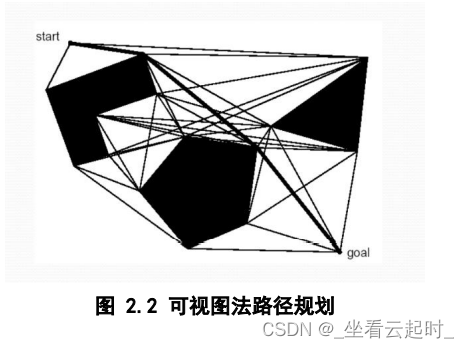
(1) 可视图法
可视图法由 Lozano-Perez 和 Wesley 于 1979 年在论文:《An Algorithm for Planning Collision-Free Paths among Polyhedral Obstacles.》中提出。将机器人看作是一个 质点,障碍物看作是规则的多边形,分别把初始点、各多边形的各个顶点和目标 点之间用直线相连,直线不能穿过障碍物,这样得到的一张图即为可视图。[2] 再经过优化,把一些不必要的连线去掉,由出发点沿着所连的直线就可以到达目 标点,该路径就是一条无碰撞的可行路径,这就是可视图法。如图所示。
(2) 栅格法
采用正方形栅格表示环境,每个栅格有一个表征值 CV,表示在此方格中障 碍物对于机器人的危险程度,对于高 CV 值的栅格位置,机器人优先躲避,CV 值按其距机器人的距离被事先划分为若干等级。每个等级对机器人的躲避方向会 产生不同影响。
障碍物的位置一旦被确定,就按照一定的衰减方式赋给障碍物本身及其周围栅格一定的值,每个栅格的值代表了该位置有障碍物的可能性。栅格具有简单、 实用、操作方便的特点,完全能够满足使用要求。
(3) 自由空间法
主要思想是把障碍物按照一定的比例进行扩大,再把机器人按照合适比例缩小,再用设定好的凸多边形来描述机器人和环境,以此来解决路径规划问题,优点是构建连通图方便,缺点是当障碍物比较多的时候,算法复杂度较高,运行效率低下。
2.2 局部路径规划算法
2.2.1启发式算法
(1)遗传算法
Holland 于 1975 年首次提出遗传算法,是模仿生物进化中的基因遗传和优胜劣汰等过程的一种仿生学优化搜索算法。遗传算法通过模拟一个人工种群进化过程,通过选择( Selection) 、交 叉 ( Crossover) 以及变异( Mutation) 等机制,不断迭代搜索出近似最优解,进而达到求解的目的。 遗传算法进行搜索时首先要对种群进行初始化,而且需要确定问题求解的编码和解码过程,一般情况下采取实数编码或二进制编码,对于每一次迭代过程,遗传算法需要计算个体的适应度,也就是个体对于问题的匹配程度。适应度的值越大,解的质量就越高。 每一次迭代,种群需要经历选择、交叉、变异三个步骤。选择即从种群中选出适应性较好的个体,淘汰适应性较差的个体传入下一代种群。交叉即对个体对中的基因序列进行交换,通过交叉,遗传算法对解的搜索能力得到有效提高。[3] 变异即对个体基因序列中的基因值进行变动,使得算法具有局部的随机搜索能力,并能够维持群体的多样性,防止算法出现过早收敛的情况。 在迭代次数或者种群中最优个体的适应度达到一定阈值后算法终止。种群中适应度最高的个体就 是求得的相对最优解。
(2)粒子群算法
粒子群算法是一种基于群智能的随机优化算法,于1995 年由Kennedy和Eberhart提出。 该算法具有高效并行、流程简单、易于编程实现等特点,适于非线性优化问题的求解。 其思想来源于对鸟群捕食行为的模拟,优化问题的潜在解通常称为“粒子”,粒子属性可通过位置、速度和适应度函数进行描述。
(3)蚁群算法
又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法。它由Marco Dorigo于1992年在他的博士论文“Ant system: optimization by a colony of cooperating agents”中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为。蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质。针对PID控制器参数优化设计问题,将蚁群算法设计的结果与遗传算法设计的结果进行了比较,数值仿真结果表明,蚁群算法具有一种新的模拟进化优化方法的有效性和应用价值。
2.2.2 神经网络算法
人工神经网络(Artificial Neural Networks,ANN)系统是 20 世纪 40 年代后出现的。它是由众多的神经元可调的连接权值连接而成,具有大规模并行处理、分布式信息存储、良好的自组织自学习能力等特点。BP(Back Propagation)算法又称为误差 反向传播算法,是人工神经网络中的一种监督式的学习算法。BP 神经网络算法在理论上可以逼近任意函数,基本的结构由非线性变化单元组成,具有很强的非线性映射能力。而且网络的中间层数、各层的处理单元数及网络的学习系数等参数可根据具体情况设定,灵活性很大,在优化、信号处理与模式识别、智能控制、故障诊断等许 多领域都有着广泛的应用前景。
2.2.3 人工势场法
人工势场实际上是对机器人运行环境的一种抽象描述。在势场中包含斥力和引力极,不希望机器人进入的区域的障碍物属于斥力极,子目标及建议机器人进入的区域为引力极。引力极和斥力极的周围由势函数产生相应的势场。机器人在势场中具有一定的抽象势能,它的负梯度方向表达了机器人系统所受到抽象力的方向,正是这种抽象力,促使机器人绕过障碍物,朝目标前进。人工势场法规划出的路径一般平滑且安全,结构简单、易于实现,但是有产生局部最优的问题。
三.本文采用的路径规划算法——强化学习
1. 概念
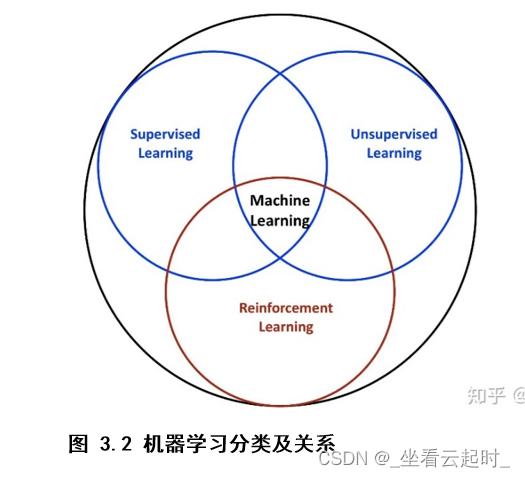
强化学习(Reinforcement Learning ,RL),是一种重要的机器学习方法,机器学习分为监督学习、无监督学习、强化学习三种。强化学习是系统从环境到行为映射的学习,目的是使奖励信号(强化信号)函数值最大。[4] 换句话说,强化学习是一种学习如何从状态映射到行为以使得获取的奖励最大的学习机制。一个动作需要不断在环境中进行实验,环境对动作做出奖励,系统通过环境的奖励不断优化行为,反复实验,延迟奖励。
2. 与其他机器学习方式的区别
也就是说与监督学习、无监督学习有什么不同之处。监督学习的训练集中,每一个样本都被打上标签,标签指代的是正确的结果。监督学习让系统按照每个样本所对应的标签推断出应有的反馈机制,进而在没有打过标签的样本上也能计算出正确结果。典型算法有:决策树、支持向量机(SVM)、k-近邻算法(KNN)等。无监督学习是从无标签的数据集中发现隐藏的结构,典型的例子就是聚类问题。常见算法有k-均值(K-means)、DBSCAN密度聚类算法、最大期望算法等。
强化学习在交互中不存在监督学习中的正确标签,而是在自身的经验中去学习。强化学习的目标也不是寻找隐藏的结构,而是最大化奖励。
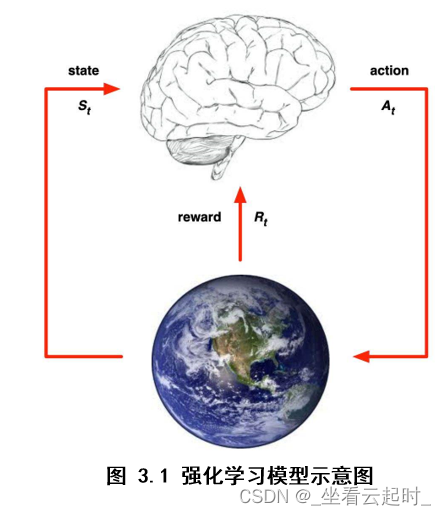
3. 强化学习模型
主体(Agent)通过与环境(environment)交互进行学习,交互包括行动(action),奖励(reward),状态(state)。交互过程表述如下:每一步主体都根据策略选择一个行动方式执行,比如说向前走、向后走,然后感知做出该行动后的立即奖励,还有下一步的状态,该状态也就是环境的状态,通过已有的经验再修改自己的策略做出下一个动作,经验就是根据这一步一步的动作学习来的,每一步都积累一些奖励值(立即奖励),目标就是让累积的奖励值最大。
假设主体所处的环境被描述为状态集S,可以执行的任意的动作集合A。下面描述强化学习模型运作过程:
强化学习系统(在主体上运作)接受环境状态的输入s,根据内部的推理机制,系统给出相应的动作a,环境在系统动作a下由s变迁到新的状态s’ ,系统再接受环境新状态的输入,同时得到环境对于系统刚才动作的立即奖励r。每次在某状态下执行动作
,主体会收到一个立即奖励
,环境变迁到新的状态
。如此产生了一系列的状态
,动作
和立即奖励
的集合,如图:
强化学习系统的目标是学习一个行为策略Π:S—>A,这个策略不是具体的某个动作,更像是一种决策的经验集合,根据这个策略,系统每一步都能做出让环境奖励累积值达到最大的动作。这个环境奖励累积值可以表示为:+γ
+
+…(0lineEdit_2->setText(buffer1);
用sprintf函数把整形变量转化为字符型,存在字符数组中再显示在控件上。
各种点的UI,包括起始点,轨迹,终止点,障碍物,选中点:
先上代码:
enum CellType
2. {
3. Null = 0 , Barrier = 1 , Candidate = 2, Path = 3, Selected=4, Start=5 ,End=6, Win=7
4. } type;
5.
6. void MessageControl::setCellType(CellType type)
7. {
8.
9. this->type = type;
10. if(type == MessageControl::Null)
11. {
12.
13. ui->widget->setStyleSheet(QString("background-color:%1;").arg(defaultColor.name())); // 设置背景色
14.
15. }
16. if(type == MessageControl::Barrier)
17. {
18. ui->widget->setStyleSheet(QString("background-color:%1;").arg(barrierColor.name())); // 设置背景色
19.
20.
21. }
22. if(type == MessageControl::Candidate)
23. {
24. ui->widget->setStyleSheet(QString("background-color:%1;").arg(candidateColor.name())); // 设置背景色
25.
26. }
27. if(type == MessageControl::Path)
28. {
29.
30. ui->widget->setStyleSheet(QString("background-color:%1;").arg(pathColor.name())); // 设置背景色
31.
32. }
33. if(type == MessageControl::Selected)
34. {
35. ui->widget->setStyleSheet(QString("background-color:%1;").arg(selectedColor.name())); // 设置背景色
36.
37. }
38. if(type == MessageControl::Start)
39. {
40. MessageControl::palette.setBrush(QPalette::Active, QPalette::Base, QBrush(Qt::green)); // 设置背景色
41. this->setPalette(palette);
42. }
43. if(type == MessageControl::End)
44. {
45. MessageControl::palette.setBrush(QPalette::Active, QPalette::Base, QBrush(Qt::blue)); // 设置背景色
46. this->setPalette(palette);
47. }
48. if(type == MessageControl::Win)
49. {
50. ui->widget->setStyleSheet(QString("background-color:%1;").arg(winColor.name())); // 设置背景色
51. }
52. }
思路就是为函数setCellType(CellType type)传进去一个参数,这个参数的数据类型在.h文件中定义过了,是一个元素类型,有起始点(Start)、终止点(End)、障碍物(barrier)、轨迹(Path)等,都可以用数字来表示,传到函数中之后,函数会根据type来设置对应的颜色。那么如何跟单元格选中关联起来呢,如何通过鼠标触发呢?
QT有一个与众不同的“信号和槽”机制,用connect函数可以将两个不同文件中的函数连接在一起,一个函数作为信号发出者,在发送方.h文件中定义为signal,另一个函数作为槽,接收信号,在接收方.h文件中定义为slot。
比如:
发送方: messagecontrol文件

接收方: mainwindow文件

关于QT信号与槽机制具体内容可以查看参考文献[7]。
1. //鼠标控制栅格选择
2. void MessageControl::mousePressEvent(QMouseEvent *event) //摁住鼠标事件
3. {
4. if(this->type == MessageControl::Selected) //如果已经选中了。再次点击及取消选中状态
5. {
6. this->setCellType(MessageControl::Null);
7. emit this->selectedCancelIndex(pos_y,pos_x); //给mainwindows类发送一个信号
8. }
9. else
10. {
11. this->setCellType(MessageControl::Selected);
12. emit this->selectedCellIndex(pos_y,pos_x); //给mainwindows类发送一个信
13. }
14. }
鼠标选中单元格时,会把该单元格坐标pos_x,pos_y传入信号函数,发送给mainwindow,这里emit就是发送信号的意思,mainwindow中的对应槽函数就会接收到参数,将该单元格坐标加入到已选中坐标数组中,同时给setCellType传入颜色参数,使其变色。
2.机器人路径规划算法设计
2.1 机器人行进方式
八叉树的方式行进,可以有八个运动方向:
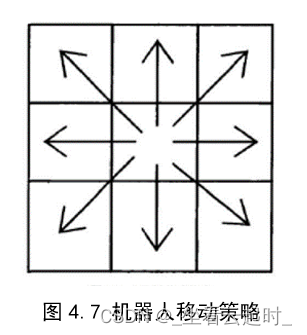
用八个常量代表八个方向:
1. const int up=1; 2. const int down =2; 3. const int Left =3; 4. const int Right=4; 5. const int leftup=5; 6. const int leftdown=6; 7. const int rightup=7; 8. const int rightdown=8;
2.2 变量设置:
1. double R=0.8; //折扣因子
2. int flag=1; //用来记录机器人是否位置改变,1为改变
3. int over; //判定是否到达终点
4. double length=0.0; //打印路径长度
5. double Qtable[TABLE_COLUMN+2][TABLE_ROW+2][8]={0.0}; //存放奖励函数Q的表,每次训练更新一遍,8(方向)+1(障碍)+4(边沿)=13
6. double r[TABLE_COLUMN+2][TABLE_ROW+2]={0.0};
7. double action(int act , int& x,int& y,int& den);
8. void initplace(int& x,int& y,int& den);
9. double get_expected_max_reward(int x,int y);
10. void actpunish();
- R:折扣因子,用来为每一次的延迟奖励打折扣;
- flag: 用来判定机器人目前位置相对于上次的位置是否发生改变,初始设置为1,代表发生改变;
- over: 判断机器人是否到终点的值;
- Qtable: Q值表,每一个单元格有八个对应的Q值,分别代表向一个方向行进的Q值是多少。比如Qtable[0][0][1]就代表在坐标(0,0)处,向上走的Q值是多少;
- r[][]: 立即奖励值,每走到一个单元格,环境都给一个立即奖励;
- Initplace:初始化,把起始点、终止点、over都初始化;
剩下几个函数前面介绍过了。
!注意:
采用 ε- 贪心策略选择动作 a,在状态 s 下执行当前动作 a,得到新状态 s' 和奖励 R。贪心系数Greedy =0.2。Q-learning本质上是贪心算法。但是如果每次都取预期奖励最高的行为去做,那么在训练过程中可能无法探索其他可能的行为,甚至会进入“局部最优”,无法完成游戏。所以,由贪心系数,使得机器人有Greedy的概率采取最优行为,也有一定概率探索新的路径。
2.3 算法步骤
(1)Action:机器人从起始点出发,有一定概率随机选择运动方向,否则向Q值最大的方向前进
(2)Reward:如果遇到边界或障碍,机器人不动,返回一个惩罚值,使该处该动作的Q值减小,下次尽量不做出该动作。
Environment:如果正常前进,根据做出的动作,由公式
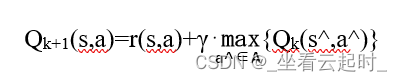
算出上一步所在格子的Q表值。
(4)超过步数限制(200步),则寻径失败。
算法流程图如下(一次训练):
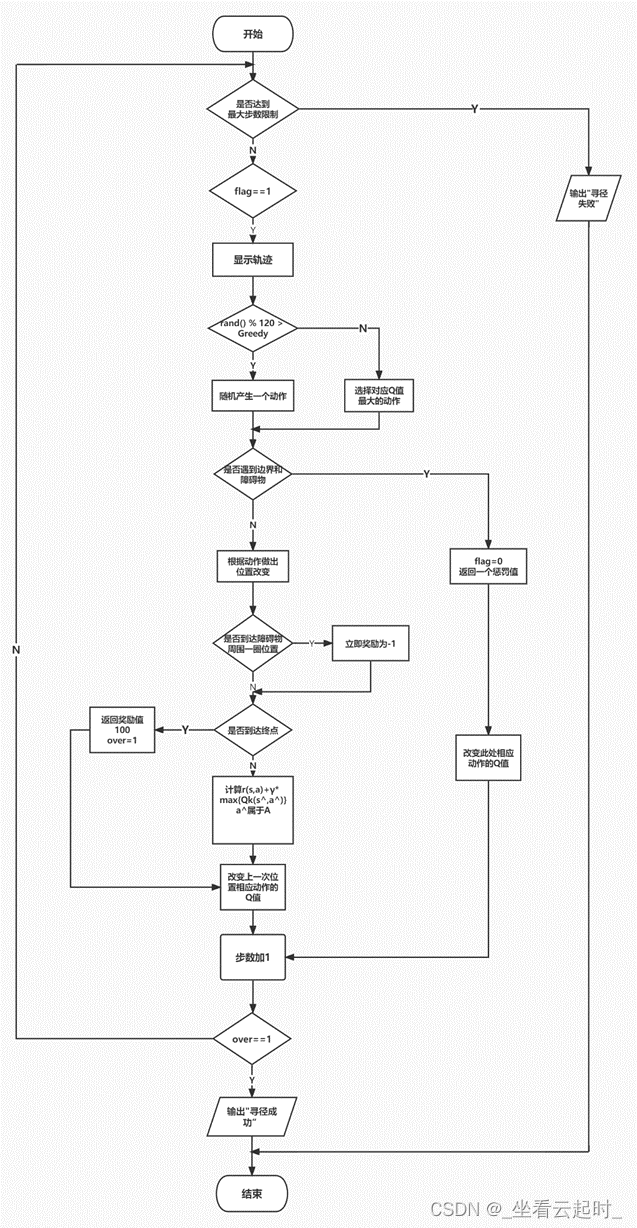 图 4.8 路径规划算法流程图
图 4.8 路径规划算法流程图
算法代码:
1. //强化学习寻径算法 2. void MainWindow::Reinforce() 3. { 4. 5. Q.actpunish(); //初始化边界惩罚值 6. int wintimes=0; //定义成功次数变量 7. int traintimes = QInputDialog::getInt(this, 8. "QInputdialog_Name", 9. "请输入要训练的次数", 10. QLineEdit::Normal, 11. 1, 12. 5000); 13. 14. for(int i=1;isetCellType(MessageControl::Null); 29. if(i==0 && j==0) 30. t_MessageControl->setCellType(MessageControl::Start); 31. if(i==TABLE_ROW && j==TABLE_COLUMN) 32. t_MessageControl->setCellType(MessageControl::End); 33. 34. } 35. } 36. 37. 38. //障碍物标记保留 39. for(auto t:Q.barrier_xy) 40. { 41. MessageControl* t_MessageControl =(MessageControl *)(ui->tableWidget->cellWidget(t.x(),t.y())); 42. t_MessageControl->setCellType(MessageControl::Barrier) 43. } 44. 45. 46. //当训练次数为10的倍数时,打印在框里 47. if(i % 10 == 0) 48. { 49. char buffer[256]; 50. sprintf(buffer,"训练次数为: %d\n",i); 51. ui->lineEdit->setText(buffer); 52. } 53. 54. //设置一个messagecontrol对象在目前所在格子 55. MessageControl* t_MessageControl =(MessageControl*) ui->tableWidget->cellWidget(Q.arrived_xy.at(0).x(),Q.arrived_xy.at(0).y()); 56. 57. for(int j = 0; j lineEdit_2->setText(buffer1); 66. } 67. 68. int regx=Q.arrived_xy.at(0).x(); int regy=Q.arrived_xy.at(0).y(); //提取此时坐标,后面传参要用 69. int regtwicex=regx; int regtwicey=regy; //再次暂存此时坐标,后面更新Q表要用 70. double nextmax = -100; 71. 72. if(Q.flag==1) 73. { 74. MessageControl* t_MessageControl =(MessageControl*) ui->tableWidget->cellWidget(Q.arrived_xy.at(0).x(),Q.arrived_xy.at(0).y()); 75. //如果位置改变显示轨迹 76. t_MessageControl->setCellType(MessageControl::Path); 77. 78. } 79. //有概率随机产生一个动作 80. if(rand() % 80 > Greedy) 81. { 82. op = rand() % 8 + 1; 83. } 84. 85. //如果不随机,寻找Q值最大的动作走 86. else 87. { 88. for (int m = 1; m cellWidget(Q.arrived_xy.at(0).x(),Q.arrived_xy.at(0).y()); 108. t_MessageControl->setCellType(MessageControl::Win); 109. QMessageBox MyBox(QMessageBox::NoIcon,"提示","正确,寻径成功"); 110. MyBox.exec(); 111. break; 112. } 113. 114. 115. } 116. char bufferwintimes[256]; 117. sprintf(bufferwintimes,"成功次数为: %d\n",wintimes); //展示成功次数 118. ui->lineEdit_wintimes->setText(bufferwintimes); 119. 120. if(Q.over != 1) 121. { 122. QMessageBox::critical(this,"错误","找不到路径"); 123. //控件还原 124. ui->tableWidget->setEnabled(true); 125. ui->pushButton_barrier->setEnabled(true); 126. ui->pushButton_clear->setEnabled(true); 127. ui->lineEdit->setEnabled(true); 128. ui->pushButton_find->setText("开始寻路 (Enter)"); 129. } 130. 131. 132. //打印Qtable 133. //创建文件对象,指定文件位置 134. QFile file("D:/Qt/project/robotpath/algorithmdata.txt"); 135. //对文件进行写操作 136. if(!file.open(QIODevice::WriteOnly|QIODevice::Text|QIODevice::Append)) 137. { 138. QMessageBox::information(this,"警告","请选择正确的文件!"); 139. } 140. else 141. { 142. QTextStream stream( &file ); 143. stream
")
")
")

还没有评论,来说两句吧...