

Hadoop+Spark大数据技术 第三次作业





-
第三次作业
-
1.简述HDFS Shell三种操作命令hadoop fs、hadoop dfs、hdfs dfs的异同点。
-
相同点
-
用于与 Hadoop 分布式文件系统(HDFS)交互。可以执行各种文件系统操作,如文件复制、删除、移动等。
(图片来源网络,侵删)
-
-
不同点
-
hadoop fs、hadoop dfs已弃用,新版本推荐使用hdfs dfs。
-
-
-
2.简述常用HDFS Shell 用户命令及其功能,简述HDFS 管理员命令的作用。
-
2.3.2 HDFS常用的Shell 操作
-
1.创建目录——mkdir 命令
-
2.列出指定目录下的内容——ls命令
-
3.上传文件——put命令
(图片来源网络,侵删) -
4.从HDFS中下载文件到本地文件系统——get命令
-
5.复制文件——cp命令
-
6.查看文件内容——cat命令
-
7.在HDFS目录中移动文件——mv命令
-
8、显示文件大小——du命令
-
9.追加文件内容——appendToFile命令
-
10.从本地文件系统中复制文件到HDFS——copyFromLocal命令
-
11.从HDFS中复制文件到本地文件系统—copyToLocal命令
-
12.从HDFS中删除文件和目录——rm命令
-
-
管理员命令(dfsadmin)
-
1.查看文件系统的基本信息和统计信息——report命令
-
查看HDFS状态,比如有哪些DataNode、每个DataNode的情况
-
-
2.安全模式——safemode命令
-
-
-
3.简述HDFS文件操作主要涉及的Java类和FileSystem对象的常用方法。
-
主要涉及的Java类
-
org.apache.hadoop.con.Configuration
-
作用该类的对象封装了客户端或者服务器的配置
-
-
org.apache.hadoop.fs.FileSystem
-
该类的对象是一个文件系统对象,可以用该对象的一些方法对文件进行操作。
-
-
org.apache.hadoop.fs.FileStatus
-
用于向客户端展示系统中文件和目录的元数据,具体包括文件大小、数据块大小、副本信息、所有者、修改时间等。
-
-
org.apache.hadoop.fs.FSDatalnputStream
-
文件输入流,用于读取Hadoop文件
-
-
org.apache.hadoop.fs.FSDataOutputStream
-
文件输出流,用于写人Hadoop文件
-
-
org.apache.hadoop.fs.Path
-
用于表示Hadoop文件系统中的文件或者目录的路径
-
-
-
通过FileSystem 对象的一些方法可以对文件进行操作,常用方法如
-
copyFromLocalFile(Path src, Path dst)
-
从本地文件系统复制文件到HDFS
-
-
copyToLocalFile(Path src, Path dst)
-
从HDFS复制文件到本地文件系统
-
-
mkdirs(Path f)
-
建立子目录
-
-
rename(Path src, Path dst)
-
重命名文件或文件夹
-
-
delete(Path f)
-
删除指定文件
-
-
-
-
4.编写利用Java API实现上传文件至HDFS的Java程序。
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; public class HdfsFileUploader { public static void main(String[] args) { // 设置 Hadoop 配置信息 Configuration conf = new Configuration(); // 设置 HDFS 地址 conf.set("fs.defaultFS", "hdfs://localhost:9000"); // 创建 HDFS 文件系统对象 FileSystem fs = null; try { fs = FileSystem.get(conf); // 本地文件路径 Path srcPath = new Path("local/path/to/your/file.txt"); // HDFS 目标路径 Path destPath = new Path("/path/in/hdfs/destination/file.txt"); // 调用文件上传方法 uploadFile(fs, srcPath, destPath); System.out.println("文件上传成功!"); } catch (IOException e) { e.printStackTrace(); System.out.println("文件上传失败:" + e.getMessage()); } finally { // 关闭 FileSystem 对象 if (fs != null) { try { fs.close(); } catch (IOException e) { e.printStackTrace(); } } } } // 文件上传方法 public static void uploadFile(FileSystem fs, Path srcPath, Path destPath) throws IOException { // 将本地文件上传至 HDFS fs.copyFromLocalFile(srcPath, destPath); } } -
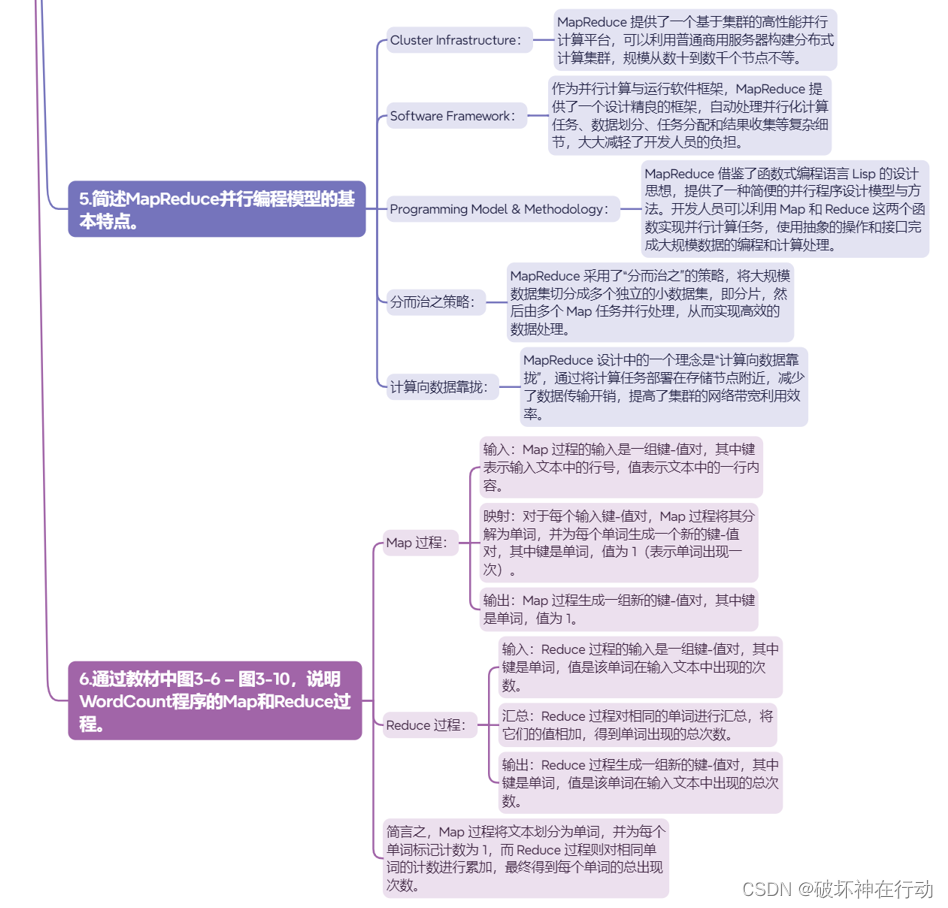
5.简述MapReduce并行编程模型的基本特点。
-
Cluster Infrastructure:
-
MapReduce 提供了一个基于集群的高性能并行计算平台,可以利用普通商用服务器构建分布式计算集群,规模从数十到数千个节点不等。
-
-
Software Framework:
-
作为并行计算与运行软件框架,MapReduce 提供了一个设计精良的框架,自动处理并行化计算任务、数据划分、任务分配和结果收集等复杂细节,大大减轻了开发人员的负担。
-
-
Programming Model & Methodology:
-
MapReduce 借鉴了函数式编程语言 Lisp 的设计思想,提供了一种简便的并行程序设计模型与方法。开发人员可以利用 Map 和 Reduce 这两个函数实现并行计算任务,使用抽象的操作和接口完成大规模数据的编程和计算处理。
-
-
分而治之策略:
-
MapReduce 采用了“分而治之”的策略,将大规模数据集切分成多个独立的小数据集,即分片,然后由多个 Map 任务并行处理,从而实现高效的数据处理。
-
-
计算向数据靠拢:
-
MapReduce 设计中的一个理念是“计算向数据靠拢”,通过将计算任务部署在存储节点附近,减少了数据传输开销,提高了集群的网络带宽利用效率。
-
-
-
6.通过教材中图3-6 – 图3-10,说明WordCount程序的Map和Reduce过程。
-
Map 过程:
-
输入:Map 过程的输入是一组键-值对,其中键表示输入文本中的行号,值表示文本中的一行内容。
-
映射:对于每个输入键-值对,Map 过程将其分解为单词,并为每个单词生成一个新的键-值对,其中键是单词,值为 1(表示单词出现一次)。
-
输出:Map 过程生成一组新的键-值对,其中键是单词,值为 1。
-
-
Reduce 过程:
-
输入:Reduce 过程的输入是一组键-值对,其中键是单词,值是该单词在输入文本中出现的次数。
-
汇总:Reduce 过程对相同的单词进行汇总,将它们的值相加,得到单词出现的总次数。
-
输出:Reduce 过程生成一组新的键-值对,其中键是单词,值是该单词在输入文本中出现的总次数。
-
-
简言之,Map 过程将文本划分为单词,并为每个单词标记计数为 1,而 Reduce 过程则对相同单词的计数进行累加,最终得到每个单词的总出现次数。
-
-


")
")


还没有评论,来说两句吧...