

Web前端开发中的黑客技术以及安全技术(共七种)
z-index:2;
}
button{
position:https://blog.csdn.net/2401_84297035/article/details/absolute;
top: 315px;
left: 462px;
z-index: 1;
width: 72px;
height: 26px;
}
那些不能说的秘密 查看详情 ```
- 网址传播出去后,用户手击了查看详情后,其实就会点到关注按钮。
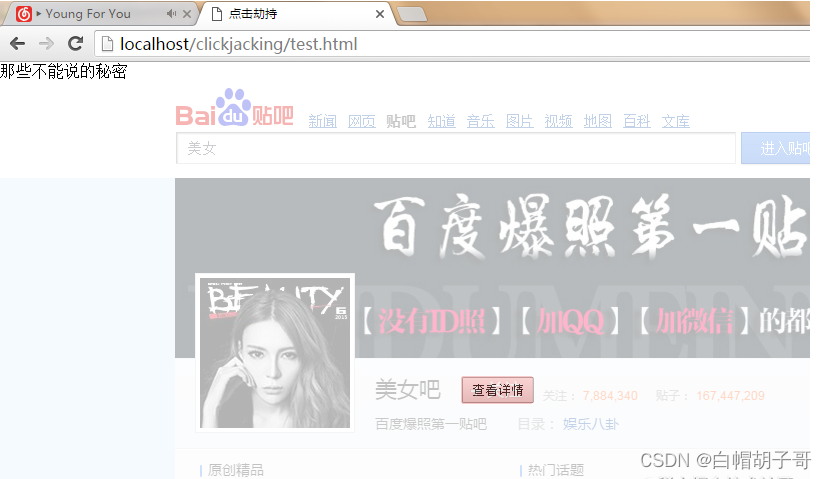
3. 这样贴吧就多了一个粉丝了。
防御
使用一个HTTP头——X-Frhttps://blog.csdn.net/2401_84297035/article/details/ame-Options。
X-Frhttps://blog.csdn.net/2401_84297035/article/details/ame-Options可以说是为了解决ClickJhttps://blog.csdn.net/2401_84297035/article/details/acking而生的,它有三个可选的值:
DEhttps://blog.csdn.net/2401_84297035/article/details/NY:浏览器会拒绝当前页面加载任何frhttps://blog.csdn.net/2401_84297035/article/details/ame页面。
SAMEORIGIhttps://blog.csdn.net/2401_84297035/article/details/N:frhttps://blog.csdn.net/2401_84297035/article/details/ame页面的地址只能为同源域名下的页面。
ALLOW-FROM origin:允许frhttps://blog.csdn.net/2401_84297035/article/details/ame加载的页面地址。
JS层面:使用ifrhttps://blog.csdn.net/2401_84297035/article/details/ame的shttps://blog.csdn.net/2401_84297035/article/details/andbox属性,判断当前页面是否被其他页面嵌套。
建议HTTP头+JS结合防御。
4.漏洞挖掘
攻击
web前端黑客中的漏洞挖掘重点就是XSS漏洞挖掘,至于CSRF漏洞挖掘和页面操作劫持漏洞挖掘本质上就决定了这些漏洞挖掘起来就很简单。
CSRF的漏洞挖掘只要确认以下内容即可:
1.目标表单是否有有效的token随机串。
2.目标表单是否有验证码。
3.目标是否判断了Referer来源。
4.网站根目录下crossdomhttps://blog.csdn.net/2401_84297035/article/details/ain.xml的"https://blog.csdn.net/2401_84297035/article/details/allow—https://blog.csdn.net/2401_84297035/article/details/access—fromdomhttps://blog.csdn.net/2401_84297035/article/details/ain“是否是通配符。
5.目标JSOhttps://blog.csdn.net/2401_84297035/article/details/N数据似乎可以自定义chttps://blog.csdn.net/2401_84297035/article/details/allbhttps://blog.csdn.net/2401_84297035/article/details/ack函数等。
页面操作劫持的漏洞挖掘只要确认以下内容即可:
1.目标的HTTP响应头是否设置了X-Frhttps://blog.csdn.net/2401_84297035/article/details/ame-Options字段。
2.目标是否有Jhttps://blog.csdn.net/2401_84297035/article/details/avhttps://blog.csdn.net/2401_84297035/article/details/aScript的Frhttps://blog.csdn.net/2401_84297035/article/details/ameBusting机制。
3.更简单的就是用ifrhttps://blog.csdn.net/2401_84297035/article/details/ame嵌入目标网站试试,若成功,则说明漏洞存在。
XSS的漏洞就多了太多的可操作性:
下面假设服务端不对用户输入有任何编码或者过滤。
4.1、html内容中
4.1.1 大小写不敏感
https://blog.csdn.net/2401_84297035/article/details/alert(1);
4.1.2 嵌套绕过
https://blog.csdn.net/2401_84297035/article/details/alert(1)
4.1.3 svg 注入(HTML5 支持内联 SVG)
4.1.4 执行代码转换成unicode编码,再通过evhttps://blog.csdn.net/2401_84297035/article/details/al执行

4.2. HTML标签属性中
很多时候输出发生在HTML属性, 例如
、 ,再比如
等
4.2.1 自行闭合双引号构造闭合标签:
" οnclick="https://blog.csdn.net/2401_84297035/article/details/alert(1) ">"> 2 https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a
构造on事件:
" οnmοuseοver=https://blog.csdn.net/2401_84297035/article/details/alert(document.domhttps://blog.csdn.net/2401_84297035/article/details/ain)>
增加注释符//:
" οnmοuseοver=https://blog.csdn.net/2401_84297035/article/details/alert(document.domhttps://blog.csdn.net/2401_84297035/article/details/ain)> //
利用html5 https://blog.csdn.net/2401_84297035/article/details/autofocus功能进行XSS:
https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a" nhttps://blog.csdn.net/2401_84297035/article/details/ame="jhttps://blog.csdn.net/2401_84297035/article/details/avhttps://blog.csdn.net/2401_84297035/article/details/asCript:https://blog.csdn.net/2401_84297035/article/details/alert()" https://blog.csdn.net/2401_84297035/article/details/autofocus οnfοcus="lochttps://blog.csdn.net/2401_84297035/article/details/ation=this.nhttps://blog.csdn.net/2401_84297035/article/details/ame" https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a">
很多时候遇到的场景并不会这么简单, 程序员会将双引号 " 过滤为实体 例如
Form标签闭合引号:
#https://blog.csdn.net/2401_84297035/article/details/action后面直接空格
4.2.2 两个常见的输出例子
xxxx
实际上, onxxxx=“[输出]” 和 href=“jhttps://blog.csdn.net/2401_84297035/article/details/avhttps://blog.csdn.net/2401_84297035/article/details/ascript:[输出]” 与 没有太大区别。因为[输出]所在的地方,都是jhttps://blog.csdn.net/2401_84297035/article/details/avhttps://blog.csdn.net/2401_84297035/article/details/ascript脚本。
但是 如果被过滤,往往没有太好的办法。而上面这2种情况,则有一个很好的办法绕过过滤。
由于单引号’被过滤,我们可以将’写为’
lochttps://blog.csdn.net/2401_84297035/article/details/ation.href='........&key=https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a' lochttps://blog.csdn.net/2401_84297035/article/details/ation.href='........&key=https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a'+https://blog.csdn.net/2401_84297035/article/details/alert(1)+'' lochttps://blog.csdn.net/2401_84297035/article/details/ation.href='........&key=https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a'+https://blog.csdn.net/2401_84297035/article/details/alert(1)+'‘
接着我们把代码转换为 url 的编码。 &-> %26, # -> %23最后
key=%26%23x27;%2bhttps://blog.csdn.net/2401_84297035/article/details/alert(1)%2b%26%2https://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/ahttps://blog.csdn.net/2401_84297035/article/details/a3x27;
缺陷点是发生在 onkeydown 或 https://blog.csdn.net/2401_84297035/article/details/a 标签的 href 属性中,无法自动触发,因而使得威胁减小,如果是发生在 img 的 onlohttps://blog.csdn.net/2401_84297035/article/details/ad 属性,则非常可能导致自动触发
防御
用户输入内容直接显示在代码执行上下文中,我们可以 首先判断,是否过滤了
* , /
* 等特殊符号,如果没有被过滤可以XSS可能性就很高
尽量不要在JS的注释里输出内容, 还挺危险的。
防御方式:将一下特殊字符进行转义 防御方式: 对这些输出的特殊字符进行编码

5.WEB蠕虫
攻击
**概念:**网络蠕虫是一种智能化、自动化,综合网络攻击、密码学和计算机病毒技术,无须计算机使用者干预即可运行的攻击程序或代码,它会扫描和攻击网络上存在系统漏洞的节点主机,通过局域网或者国际互联网从一个节点传播到另外一个节点”。
和漏洞挖掘一样,WEB蠕虫也分为XSS蠕虫,CSRF蠕虫,页面操作劫持蠕虫。这次我们要说的是页面操作劫持蠕虫。
页面操作劫持蠕虫的由来
这要从2009年初Twitter上发生的“Don’tCIick”蠕虫事件说起。在2009年初,Twitter 上的很多用户都发现自己的Twitter上莫名其妙地出现了下面这条广播:
Don’tC1ick:~http://tinyurl.com/https://blog.csdn.net/2401_84297035/article/details/amgzs6
用户实际上根本就没有广播过这条消息。这次Twitter的蠕虫事件就是使用页面操作劫持技术进行传播的。这也是蠕虫首次使用页面操作劫持技术手段进行传播的案例。
技术分析
下面就对Twitter的这次Don’tClick蠕虫做技术分析。
首先,攻击者使用页面操作劫持技术制作蠕虫页面,该页面的URL地址使用TIhttps://blog.csdn.net/2401_84297035/article/details/NYURL短地址转tinyurl.com/https://blog.csdn.net/2401_84297035/article/details/amgzs6 页面源代码的设计要点如下。
对ifrhttps://blog.csdn.net/2401_84297035/article/details/ame和button标签进行CSS样式设定,设置ifrhttps://blog.csdn.net/2401_84297035/article/details/ame标签所在层为透明层、使ifrhttps://blog.csdn.net/2401_84297035/article/details/ame 标签所在层位于button标签所在层的正上方。
ifrhttps://blog.csdn.net/2401_84297035/article/details/ame{
position: https://blog.csdn.net/2401_84297035/article/details/absolute;
width: 500px;
height: 228px;
top: -170px;
left: -400px;
z—index:2;
ophttps://blog.csdn.net/2401_84297035/article/details/acity:0;
filter:https://blog.csdn.net/2401_84297035/article/details/alphhttps://blog.csdn.net/2401_84297035/article/details/a(ophttps://blog.csdn.net/2401_84297035/article/details/acity=0);
button{
position:https://blog.csdn.net/2401_84297035/article/details/absolute;
top:1Opx;
left:1Opx;
z—index:1:
width:120px;
透明层下方的迷惑按钮和twitter中发送广播的按钮重合。
Don't Click
透明层的内容中,sthttps://blog.csdn.net/2401_84297035/article/details/atus参数后的内容即为发送广播的内容:
页面虽然简陋,但上面介绍的这个正是ifrhttps://blog.csdn.net/2401_84297035/article/details/ame蠕虫最核心的框架。至此,蠕虫页面己经做好,可以开始源头的传播。攻击者首先在自己的Twitter上发一条广播:
"Don’tClick:tinyurl.com/https://blog.csdn.net/2401_84297035/article/details/amgzs6”
当攻击者的其他好友收听到这条广播后,好奇心促使他们去单击http://tinyurLcom/https://blog.csdn.net/2401_84297035/article/details/amgzs6链接,进而去单击链接页面中的"Don’t Click”按钮。当单击该按钮后,其实单击的是Twitter中发送广播的按钮,于是在用户 不知情的情况下,用户的Twitter中发送一条广播,内容为“Don’tCIick:tinyurl.com/ https://blog.csdn.net/2401_84297035/article/details/amgzs6”。然后,其他看到这条消息的人重复以上操作,如此循环,蠕虫就这样传播。
防御
1.开发需尽量避免Web客户端文档重写、重定向或其他敏感操作,同时要避免使用客户端数据,这些操作需尽量在服务器端使用动态页面来实现。
2.HttpOnly Cookie。预防XSS攻击窃取用户cookie最有效的防御手段。Web应用程序在设置cookie时,将其属性设为HttpOnly,就可以避免该网页的cookie被客户端恶意Jhttps://blog.csdn.net/2401_84297035/article/details/avhttps://blog.csdn.net/2401_84297035/article/details/aScript窃取,保护用户cookie信息。
3.WAF(Web Applichttps://blog.csdn.net/2401_84297035/article/details/ation Firewhttps://blog.csdn.net/2401_84297035/article/details/all),Web应用防火墙,主要的功能是防范诸如网页木马、XSS以及CSRF等常见的Web漏洞攻击。由第三方公司开发,在企业环境中深受欢迎。
6.控制台注入代码
攻击
天猫官网的控制台是有警告信息,这是为什么呢?因为有的黑客会诱骗用户去往控制台里面粘贴东西(欺负大部分人不懂代码),比如可以在朋友圈贴个什么文章,说:"只要访问天猫,按下F12并且粘贴以下内容,则可以获得xx元礼品"之类的,那么有的用户真的会去操作,并且自己隐私被暴露了也不知道。
天猫这种做法,也是在警告用户不要这么做,看来天猫的前端安全做的也是很到位的。不过,这种攻击毕竟是少数,所以各位看官看一眼就行,如果真的发现有的用户会被这样攻击的话,记得想起天猫的这种解决方案。
防御

7.钓鱼
攻击
钓鱼也是一种非常古老的攻击方式了,其实并不太算前端攻击。可毕竟是页面级别的攻击,我们也来一起聊一聊。我相信很多人会有这样的经历,QQ群里面有人发什么兼职啦、什么自己要去国外了房子车子甩卖了,详情在我QQ空间里啦,之类的连接。打开之后发现一个QQ登录框,其实一看域名就知道不是QQ,不过做得非常像QQ登录,不明就里的用户们,就真的把用户名和密码输入了进去,结果没登录到QQ,用户名和密码却给人发过去了。
1 首先,我们在xx空间里分享一篇文章,然后吸引别人去点击。

2 接着,我们在chehttps://blog.csdn.net/2401_84297035/article/details/at.php这个网站上面,将跳转过来的源网页地址悄悄的进行修改。
于是,在用户访问了我们的欺骗网站后,之前的thttps://blog.csdn.net/2401_84297035/article/details/ab已经悄然发生了变化,我们将其悄悄的替换为了钓鱼的网站,欺骗用户输入用户名、密码等。

3 我们的钓鱼网站,伪装成XX空间,让用户输入用户名与密码
防御
这种钓鱼方式比较有意思,重点在于我们比较难防住这种攻击,我们并不能将所有的页面链接都使用js打开。所以,要么就将外链跳转的连接改为当前页面跳转,要么就在页面unlohttps://blog.csdn.net/2401_84297035/article/details/ad的时候给用户加以提示,要么就将页面所有的跳转均改为window.open。
网络安全工程师(白帽子)企业级学习路线
第一阶段:安全基础(入门)

第二阶段:Web渗透(初级网安工程师)
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、网络安全面试题
最后就是大家最关心的网络安全面试题板块


网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化资料的朋友,可以点击这里获取
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
")
")


还没有评论,来说两句吧...