

Densenet+SE
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊# 前言
前言
这周开始学习关于经典模型的改进如加注意力机制,这周学习Densenet加通道注意力即SE注意力机制。
##SE注意力机制简介
SE(Squeeze-and-Excitation)注意力机制是一种用于增强卷积神经网络(CNN)性能的注意力机制,特别适用于图像分类任务。该机制由Jie Hu等人于2018年提出,旨在通过动态调整特征图中每个通道的权重,从而增强模型对重要特征的感知能力。
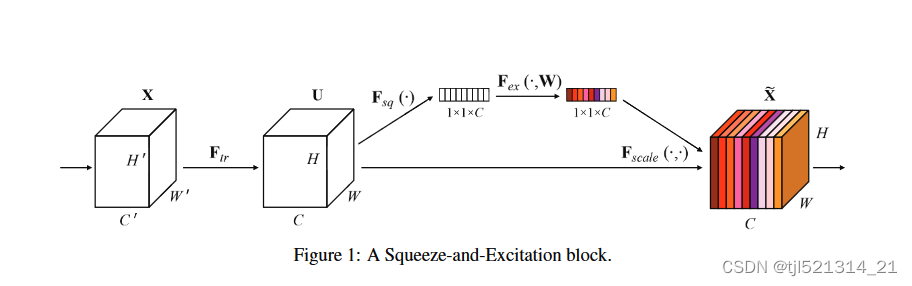
SE注意力机制的基本思想是利用全局信息来动态调整特征图中各个通道的重要性。具体来说,该机制包括两个关键步骤:Squeeze(压缩)和Excitation(激励)。
Squeeze(压缩):
在Squeeze阶段,通过全局池化操作(通常是全局平均池化)来压缩特征图在空间维度上的信息,将每个通道的特征图转换为单个数字。
假设输入特征图的尺寸为 𝐻×𝑊×𝐶其中 𝐻和 𝑊 分别是特征图的高度和宽度,𝐶是通道数。通过全局平均池化操作,将每个通道的特征图转换为长度为 𝐶的向量,表示每个通道的全局重要性。
Excitation(激励):
在Excitation阶段,利用一个小型的全连接(或者称为多层感知机)网络来学习每个通道的激励权重。将Squeeze阶段得到的长度为 𝐶 的向量输入到一个两层的全连接网络中。通过激活函数(如ReLU)和sigmoid函数,输出每个通道的激励权重(或者称为通道注意力权重)。这些权重用于对原始特征图进行加权,从而增强对重要特征的感知能力。
神经网络插入注意力机制
以resnet为例
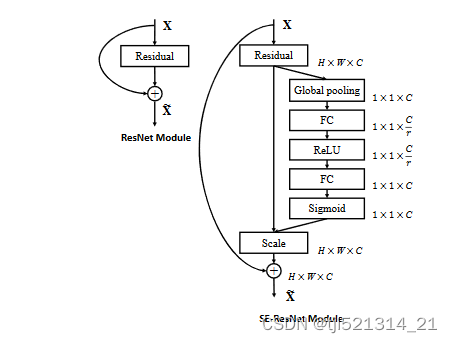
SE插入Densenet
from collections import OrderedDict import torch.utils.checkpoint as cp import torch import torch.nn as nn import torch.nn.functional as F def _bn_function_factory(norm, relu, conv): def bn_function(*inputs): concated_features = torch.cat(inputs, 1) bottleneck_output = conv(relu(norm(concated_features))) return bottleneck_output return bn_function class _DenseLayer(nn.Module): def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, efficient=False): super(_DenseLayer, self).__init__() self.add_module('norm1', nn.BatchNorm2d(num_input_features)), self.add_module('relu1', nn.ReLU(inplace=True)), self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)), self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)), self.add_module('relu2', nn.ReLU(inplace=True)), self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)), self.add_module('SE_Block', SE_Block(growth_rate, reduction=16)) self.drop_rate = drop_rate self.efficient = efficient def forward(self, *prev_features): bn_function = _bn_function_factory(self.norm1, self.relu1, self.conv1) if self.efficient and any(prev_feature.requires_grad for prev_feature in prev_features): bottleneck_output = cp.checkpoint(bn_function, *prev_features) else: bottleneck_output = bn_function(*prev_features) new_features = self.SE_Block(self.conv2(self.relu2(self.norm2(bottleneck_output)))) if self.drop_rate > 0: new_features = F.dropout(new_features, p=self.drop_rate, training=self.training) return new_features class _Transition(nn.Sequential): def __init__(self, num_input_features, num_output_features): super(_Transition, self).__init__() self.add_module('norm', nn.BatchNorm2d(num_input_features)) self.add_module('relu', nn.ReLU(inplace=True)) self.add_module('conv', nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)) self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2)) class _DenseBlock(nn.Module): def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate, efficient=False): super(_DenseBlock, self).__init__() for i in range(num_layers): layer = _DenseLayer( num_input_features + i * growth_rate, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate, efficient=efficient, ) self.add_module('denselayer%d' % (i + 1), layer) def forward(self, init_features): features = [init_features] for name, layer in self.named_children(): new_features = layer(*features) features.append(new_features) return torch.cat(features, 1) class SE_Block(nn.Module): def __init__(self, ch_in, reduction=16): super(SE_Block, self).__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局自适应池化 self.fc = nn.Sequential( nn.Linear(ch_in, ch_in // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(ch_in // reduction, ch_in, bias=False), nn.Sigmoid() ) def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x).view(b, c) # squeeze操作 y = self.fc(y).view(b, c, 1, 1) # FC获取通道注意力权重,是具有全局信息的 return x * y.expand_as(x) # 注意力作用每一个通道上 class DenseNet(nn.Module): def __init__(self, growth_rate, block_config, num_init_features=24, compression=0.5, bn_size=4, drop_rate=0, num_classes=10, small_inputs=True, efficient=False): super(DenseNet, self).__init__() assert 0
文章版权声明:除非注明,否则均为主机测评原创文章,转载或复制请以超链接形式并注明出处。
")
")


还没有评论,来说两句吧...